
[8.17] 形で覚えるDune使い方講座<初級>
Duneをマスターするための入り口へようこそ

オンチェーンとオフチェーンという言葉があるように、ブロックチェーン上のデータは従来のデータベースにある情報と違った特性を持ち合わせています。一方でそのデータ自体は従来のデータと同様に扱える部分が多くあります。
そんなオンチェーンデータを活用してブロックチェーン上のアクティビティを分析する「オンチェーン分析」という言葉を聞いたことはありますか?これからオンチェーン分析を行うためのツール「Dune Analytics」の使い方を3回に分けて紹介したいと思います。それでは早速今日はいちばん初歩的な<初級>から始めましょう。
初級が既に終わっている方はこちらから↓
![[8.18] 形で覚えるDune使い方講座<初級+>](https://substackcdn.com/image/fetch/$s_!-i8Q!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F523f618f-b99c-4d17-a903-53fb8aa1ef53_3456x1926.png)
※コードブロックを使用して説明しているため、なるべくパソコンからのアクセスをお勧めします。またこの講座を受けるためにはパソコンが必要です。
なにができるの
Dune Analytics(Dune)は自分でオンチェーン分析を行ったり、データ群をダッシュボードとして公開して可視化したり、公開されているダッシュボードを見ることでオンチェーン情報を分析することができるサービスです。
上で少し触れましたが、解析した一つ一つのデータ(例えばNFTのホルダー数、とあるトークンのtransfer回数など)を「query」と呼び、それらをまとめて一画面に表示したものを「dashboard」と言います。
3回のdune講座では自分でいくつかqueryが作成でき、dashboardを作成できるレベルまで持っていくことを目標としています。では実際にqueryを作成してみましょう。
データの取得〈SELECT, FROM〉
Duneでは、オンチェーン分析に必要なデータの取得、加工にデータベース言語の「SQL」を利用します。Solidityのような何かに特化したプログラミング言語ではなく、一般的なデータベースにも使われる汎用的な言語です。
そんなSQLを使ってオンチェーン分析を行うために、まずは解析するための元となるデータ群をオンチェーンデータから取得してくる必要があります。新しくqueryを作成し、データを取得してみましょう。

まずDuneのアカウントを持っていない人は新規登録を行なってください。Duneのトップページにアクセスし、上部の+ボタンから「New query」を押しましょう。

そうするとeditorが立ち上がり、queryの作成ができるようになります。まずはデータの取得をしてみます。今回は「OpenSea」で行われているNFTの取引データを取得して分析してみるので、まず画面左の検索フィールドからデータの取得元になりうるデータセットを検索して探します。
検索に「OpenSea」と入力して出てきた「opensea events」というデータセットを今回は利用します。まずはここからデータ取得したいときの書き方を解説します。
SELECT <何のデータ> FROM <どこから>データの取得には「SELECT」と「FROM」を使用します。FROMの後にどこからデータを取得したいかのデータセット、SELECTの後にFROMで指定したデータセットから何のデータを取得したいかを記載します。
SELECT * FROM opensea_v3_ethereum.eventsデータセットにどんな情報(column)があるのか、分析にどの情報を活用するかかがまだわからないので一般的には上記のようにSELECTの後を「*」にし、まずはデータセットにある全てのデータを取得することが一般的です。
データセットの名称は該当するデータセット名の横にある三角2つのボタンを押すと自動でeditorの中に貼り付けられます。
ここでeditor右下の「Run」を押すとデータの取得が始まるのですが、Ethereum上のOpenSeaで行われた取引の全てが取得されてしまうので、とてつもない時間を要してしまいます。なのでまずは取得するデータの数を制限して実行してみましょう。
データの制限〈LIMIT〉
データの取得数の制限を行うためには「LIMIT」の後に制限したいデータ(line)数の数字を入れるだけで大丈夫です。
LIMIT <何個に制限したいか>例えば取得したいデータ数を30個だけにしたい場合は下記のように記載します。
LIMIT 30実際に今まで説明した2行のコードを実行(Run)してみましょう。
SELECT * FROM opensea_v3_ethereum.events /* EthereumのOpenSeaから全て取得 */
LIMIT 30 /* 30個のデータに制限 */他の人のqueryを見ていると「/* */」や「--」がありますが、コードの内容に影響を及ぼさないように視認性向上のためのコメントを残すためのSQLの記法です。
ここでも解説のために何を行なっているかをコメントで残しました。
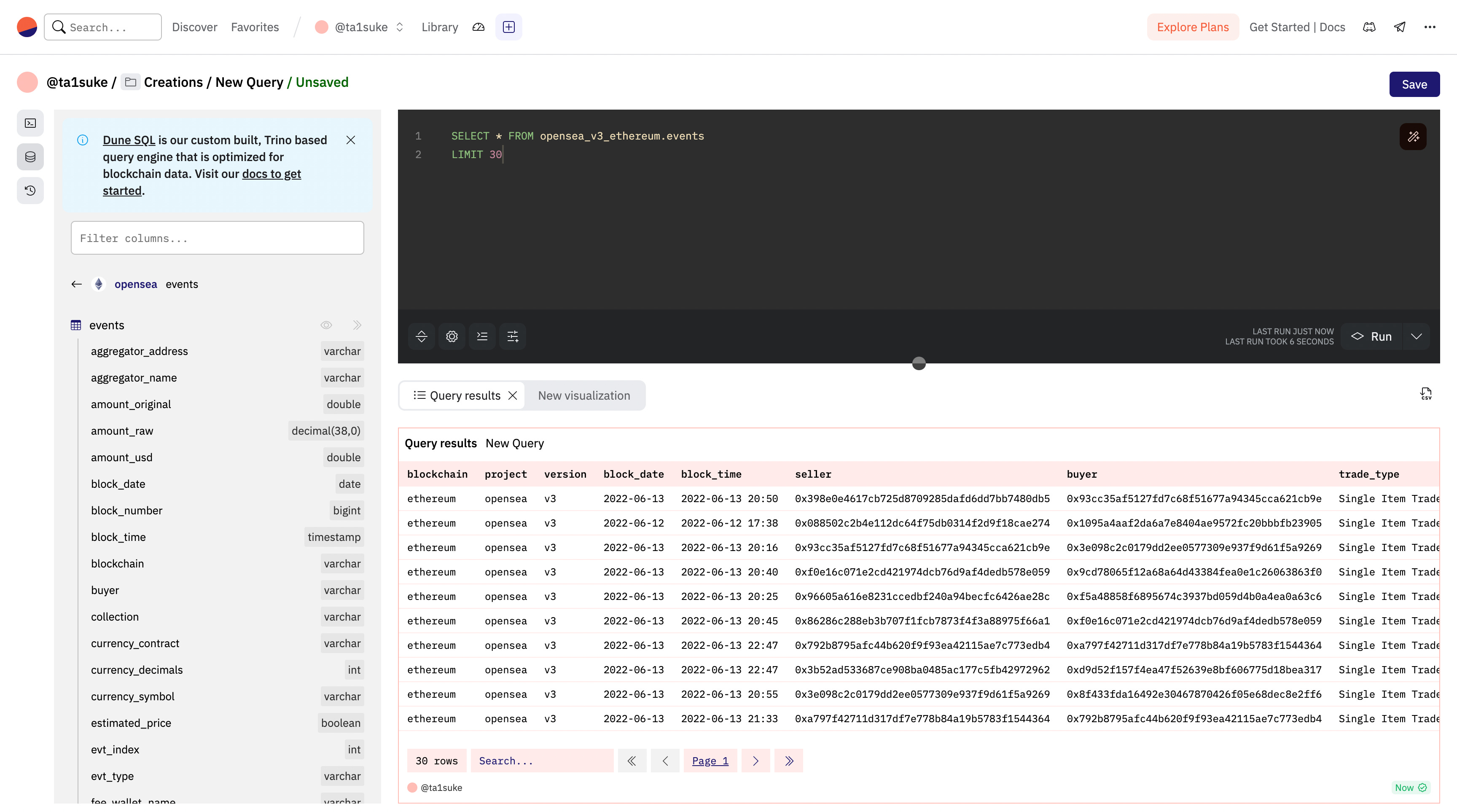
先ほどのコードを実行してみると上記のような結果になりました。特に取得するデータの発生時間の指定を行ってなかったので適当に30個のデータが取得できました。すでに出てきた時に軽く名称の紹介をしましたが、データベースには固有の2つの名称があります。
column: 縦の区切り(blockchain, project, versionなどのデータの名前の区切り)
line: 横の区切り(取引毎の区切り)
Google SheetsやExcel、Notionを使っている人は馴染みのある言葉かもしれません。
一般的なオンチェーン分析の場合に全てのcolumnが必要なことは少ないので、実行して取得したデータセットの中から必要なものだけにフィルタリングしてみましょう。
データのフィルター〈WHERE〉
取得するデータを変更したい場合はSELECTにカラム名を入れるだけでOKですが、データのフィルタリングを行いたい場合は「WHERE」を使用します。
まずはSELECTに入れてフィルタリングするケースからやってみましょう。
SELECT seller FROM opensea_v3_ethereum.events
LIMIT 15売主にあたる「seller」の情報を15個だけ取ってみます。 もちろん複数のcolumnを選択して取得することもでき、その場合は「,」をつけて並べるだけで大丈夫です。

次にデータ自体のフィルタリングをしてみましょう。私のアドレス「ta1suke.eth」が売主になっている取引を全て取得してみましょう。数は少なそうなのでLIMITは消して、SELECTの制限もせずに実行してみます。
WHERE <何が(カラム名)> = '<何のとき>'注意なのは指定する「何のとき」の部分を「’’」のシングルクォーテーションで囲む必要があるということ。実際のコードは下記のようになります。
SELECT * FROM opensea_v3_ethereum.events
WHERE seller = '0xcdaf4f9f8f9141a162f9ca7566fbacd9237718b8'実行してみた結果はこちら、私はいままでこのアドレスで4回しかNFTを売ったことがなかったようです。内容も問題なく確認できますね。

まとめ
今日のところはここらへんまでにしておきましょうか。データの取得とソートまでできたので、次は時間の指定やデータの数値の四則演算、並び替えなどを<中級>編として解説できればと思います。
ここまでで何かわからないことがあった場合は、私のX!までDMをいただけますと追加の解説を行いたいと思います。
<中級>編と<上級>編は大きなニュースや気のブレがない場合は明日明後日と連続で投稿しようと思います。まだメールアドレスの登録が完了していない方は最後に登録いただけますと嬉しいです!
次のレベルのDune講座はこちらから↓