
[8.26] これで一人前!Dune講座総集編
土日を活かしてDuneをマスターしよう!

先日までのDune講座を受講いただきましてありがとうございました。この土日で勉強してみるという方も多かったので総集編を作りました。
順番に上からやっていくと基本的に必要な全てのDune SQLが学べます。
総文字数33,000字超えのかなりのボリュームになっていますが恐らく3〜4時間のまとまった時間が取れれば問題なくできるかと思います!
分からないところがあれば私のX!でお気軽にお問合せください。最近なんかSubstackの中にもチャット機能があることを知ったのでそっちでもOKです!
なにができるの
Dune Analytics(Dune)は自分でオンチェーン分析を行ったり、データ群をダッシュボードとして公開して可視化したり、公開されているダッシュボードを見ることでオンチェーン情報を分析することができるサービスです。
上で少し触れましたが、解析した一つ一つのデータ(例えばNFTのホルダー数、とあるトークンのtransfer回数など)を「query」と呼び、それらをまとめて一画面に表示したものを「dashboard」と言います。
3回のdune講座では自分でいくつかqueryが作成でき、dashboardを作成できるレベルまで持っていくことを目標としています。では実際にqueryを作成してみましょう。
データの取得〈SELECT, FROM〉
Duneでは、オンチェーン分析に必要なデータの取得、加工にデータベース言語の「SQL」を利用します。Solidityのような何かに特化したプログラミング言語ではなく、一般的なデータベースにも使われる汎用的な言語です。
そんなSQLを使ってオンチェーン分析を行うために、まずは解析するための元となるデータ群をオンチェーンデータから取得してくる必要があります。新しくqueryを作成し、データを取得してみましょう。

まずDuneのアカウントを持っていない人は新規登録を行なってください。Duneのトップページにアクセスし、上部の+ボタンから「New query」を押しましょう。

そうするとeditorが立ち上がり、queryの作成ができるようになります。まずはデータの取得をしてみます。今回は「OpenSea」で行われているNFTの取引データを取得して分析してみるので、まず画面左の検索フィールドからデータの取得元になりうるデータセットを検索して探します。
検索に「OpenSea」と入力して出てきた「opensea events」というデータセットを今回は利用します。まずはここからデータ取得したいときの書き方を解説します。
SELECT <何のデータ> FROM <どこから>データの取得には「SELECT」と「FROM」を使用します。FROMの後にどこからデータを取得したいかのデータセット、SELECTの後にFROMで指定したデータセットから何のデータを取得したいかを記載します。
SELECT * FROM opensea_v3_ethereum.eventsデータセットにどんな情報(column)があるのか、分析にどの情報を活用するかかがまだわからないので一般的には上記のようにSELECTの後を「*」にし、まずはデータセットにある全てのデータを取得することが一般的です。
データセットの名称は該当するデータセット名の横にある三角2つのボタンを押すと自動でeditorの中に貼り付けられます。
ここでeditor右下の「Run」を押すとデータの取得が始まるのですが、Ethereum上のOpenSeaで行われた取引の全てが取得されてしまうので、とてつもない時間を要してしまいます。なのでまずは取得するデータの数を制限して実行してみましょう。
データの制限〈LIMIT〉
データの取得数の制限を行うためには「LIMIT」の後に制限したいデータ(line)数の数字を入れるだけで大丈夫です。
LIMIT <何個に制限したいか>例えば取得したいデータ数を30個だけにしたい場合は下記のように記載します。
LIMIT 30実際に今まで説明した2行のコードを実行(Run)してみましょう。
SELECT * FROM opensea_v3_ethereum.events /* EthereumのOpenSeaから全て取得 */
LIMIT 30 /* 30個のデータに制限 */他の人のqueryを見ていると「/* */」や「--」がありますが、コードの内容に影響を及ぼさないように視認性向上のためのコメントを残すためのSQLの記法です。
ここでも解説のために何を行なっているかをコメントで残しました。
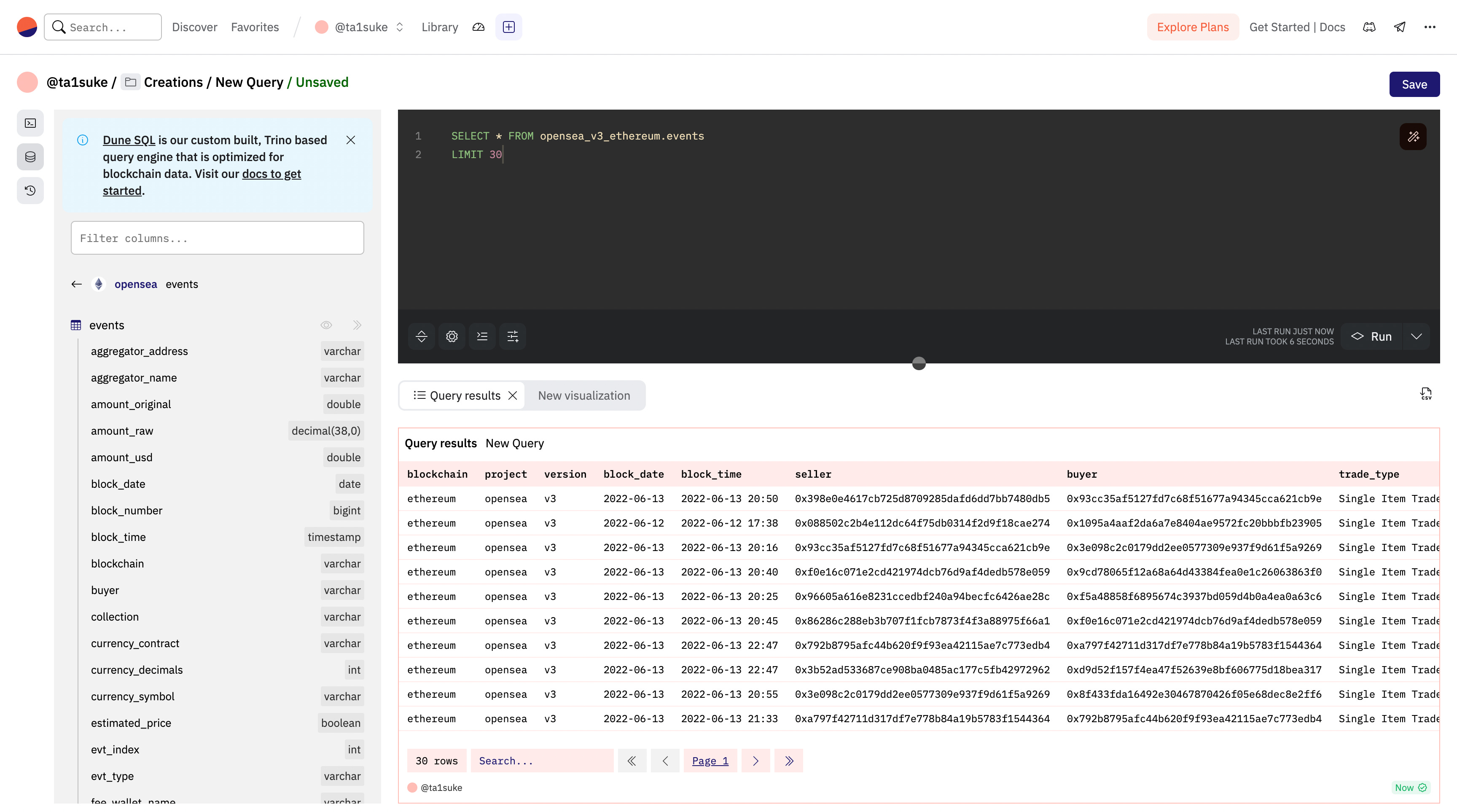
先ほどのコードを実行してみると上記のような結果になりました。特に取得するデータの発生時間の指定を行ってなかったので適当に30個のデータが取得できました。すでに出てきた時に軽く名称の紹介をしましたが、データベースには固有の2つの名称があります。
column: 縦の区切り(blockchain, project, versionなどのデータの名前の区切り)
line: 横の区切り(取引毎の区切り)
Google SheetsやExcel、Notionを使っている人は馴染みのある言葉かもしれません。
一般的なオンチェーン分析の場合に全てのcolumnが必要なことは少ないので、実行して取得したデータセットの中から必要なものだけにフィルタリングしてみましょう。
データのフィルター〈WHERE〉
取得するデータを変更したい場合はSELECTにカラム名を入れるだけでOKですが、データのフィルタリングを行いたい場合は「WHERE」を使用します。
まずはSELECTに入れてフィルタリングするケースからやってみましょう。
SELECT seller FROM opensea_v3_ethereum.events
LIMIT 15売主にあたる「seller」の情報を15個だけ取ってみます。 もちろん複数のcolumnを選択して取得することもでき、その場合は「,」をつけて並べるだけで大丈夫です。

次にデータ自体のフィルタリングをしてみましょう。私のアドレス「ta1suke.eth」が売主になっている取引を全て取得してみましょう。数は少なそうなのでLIMITは消して、SELECTの制限もせずに実行してみます。
WHERE <何が(カラム名)> = '<何のとき>'注意なのは指定する「何のとき」の部分を「’’」のシングルクォーテーションで囲む必要があるということ。実際のコードは下記のようになります。
SELECT * FROM opensea_v3_ethereum.events
WHERE seller = '0xcdaf4f9f8f9141a162f9ca7566fbacd9237718b8'実行してみた結果はこちら、私はいままでこのアドレスで4回しかNFTを売ったことがなかったようです。内容も問題なく確認できますね。

次に「WHERE」の別の使い方を見ていきましょう。先ほどは条件指定に「=」を使いましたが、ある条件に一致する時というフィルタリングをかけたと思います。実は「>, <」の不等号を利用することでデータの範囲指定をすることもできます。
WHERE <何が(カラム名)> > <何のとき> /* より大きい */
WHERE <何が(カラム名)> < <何のとき> /* より小さい */
WHERE <何が(カラム名)> >= <何のとき> /* 以上 */
WHERE <何が(カラム名)> <= <何のとき> /* 以下 */例を前回と同じデータセットで確認してみましょう。1ETH以上の取引を10個取得してみます。まずいくらで取引されたかをETH建で取得できるカラム名を探さないといけないです。こういうときは一旦「SELECT *」で取ってみるんでしたよね。
SELECT * FROM opensea_v3_ethereum.events
LIMIT 10上記のコードを実行してみて取得できたデータから、取引のETH建価格を示しているカラムは「amount_original」であることがわかりました。

それでは「1ETH以上の取引を10個」取得してみましょう。その時のコードは下記のようになります。
SELECT * FROM opensea_v3_ethereum.events
WHERE amount_original >= 1
LIMIT 10ここで注意なのは不等号の順番を間違えるとエラーが出るということ。
正: 「<=」「>=」
誤: 「=<」「=>」
実は=を先に持ってきてしまうとダメなんです。私も最初の頃はよく間違えていたのでみなさんも注意ポイントとして覚えておいていただけると嬉しいです。
そしてもう一つの注意ポイントはアドレスなどの文字列の場合は「’ ’」で囲む必要があり、数字などの値を扱う場合は「’ ’」を付けなくていいということ。初級と比べて覚えることがどんどん増えてきていますが頑張ってついてきてください!
文字列: ‘123’
値: 123
では練習として一つすることを追加します、高額なNFTといえばAZUKIやBAYCが思い浮かびますね。そんなbluechip NFTの中でも、5ETHを割り込んだdoodlesが5ETH以上で取引された事例を50個取得してみましょう。どのNFTかを指定するためにはcontract addressを含むカラムを探してみます。

ここでは「nft_contract_address」を活用するとよさそうですね。早速先ほどの条件のコードを書いてみましょう、と言いたいところですがここで「複数の条件」をよりスマートに書くための新しい文法を覚えましょう。
データを複数条件指定〈AND〉
データの指定に「WHERE」を使って複数条件指定したい場合は、日本語の「且つ」と同じ使い方で「AND」を使用します。使い方は以下のようになります。
WHERE <何が(カラム名)> = '<何のとき>' /* 条件1 */
AND <何が(カラム名)> = '<何のとき>' /* 条件2 */
AND <何が(カラム名)> = '<何のとき>' /* 条件3以降も同じ */これを踏まえた上で2回目のWHEREをANDに変えてみてdoodlesの5ETH以上の取引を50個取得してみましょう。その時のコードは下記のようになります。
SELECT * FROM opensea_v3_ethereum.events
WHERE amount_original >= 5
AND nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
LIMIT 503回目以降のWHEREも同じくANDを利用することでいくつでも取得する情報に条件を付与することができます。例えば売り主をいま表示されている取得済みのデータの中から適当に選んで指定して取得してみましょう。
SELECT * FROM opensea_v3_ethereum.events
WHERE amount_original >= 5
AND nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
AND seller = '0x6982f5da70802f882fcc2cf2f02b3ba6778cc61e'こんな感じの要領で高度な分析になるほどANDをよく使いますので、ぜひ覚えておいてください。
カラムの名前を変更〈AS〉
今後たくさんのqueryを作っていく上で元々ついているカラム名では長くて分かりにくいので、自分のわかりやすい名前に変えたくなったりするかもしれません。そういうときには「as」を使って名前を上書きすることができます。ちなみにこの機能が後々とても重要になってきます。
SELECT <この名前を> AS <この名前に> /* SELECT以外でも利用可能 */例えばCompoundのデータセット「compound_v2_ethereum.borrow」の中にある「symbol」というカラムだけを取得し、「token」という名前に変更して100個のデータを取得してみましょう。その時のコードは下記のようになります。
SELECT symbol AS token FROM compound_v2_ethereum.borrow
LIMIT 100実際に100個のデータが取得できカラム名を「token」に変更できました。みなさんは同じ画面になっていますか?

一方でこのバラバラになったトークンは全部で何種類あるんだろう、、ってときにデータをまとめる事ができるやつを次に紹介します。
カラムのユニークな値を取得〈DISTINCT〉
今日はここまでやって最後にしましょう、カラム内に同一の値や文字列がある場合は一括りにして重複がない状態で表示できます。例えばあるアドレスやトークン名などで重複があるものをまとめてユニークな値にすることができます。
SELECT DISTINCT <何を(カラム名)>実際にトークン名で「DISTINCT」してみるとコードは下記のようになります。
SELECT DISTINCT symbol AS token FROM compound_v2_ethereum.borrow
LIMIT 100実行してみたら実際に7種類のトークンが取得できました。追加でキニナル部分のそれぞれのトークンが合計で何枚動いていて、何回のトランザクションがあったかの計算は次の中級の部分で説明できればと思います。

みんなの質問回答
いくつかみなさんから質問がありましたのでそれに回答していきます。
サンプルコードと違う位置で改行してもいいですか?
もちろん大丈夫です。改行自体はコードの実行内容に影響を与えないので、自分の視認性が上がるところで改行して問題ないです。
ASの後に「’ ’」を使わないのはなぜですか?
ASの後に入力する任意の名前は文字列ではなく、カラム名のため「’ ’」を使用しません。カラム名に一時的(実行するコード内のみで有効)なニックネームをつけるみたいな。エンジニア向けの説明をするとエイリアスです。
大文字小文字を区別しますか?
大文字と小文字によって実行結果に差異は生じません。試しに下記のようにカラム名やデータセットの名前を不規則に大文字へ変更してみましたが、きちんと実行できました。視認性の問題なので自分の中でルールを決めて書くのがいいでしょう。基本的にカラム名をわざわざ大文字に直す必要ないのでそのまま使いましょう。
SELECT bOrrower, evt_bLock_timE FROM compound_v2_EthereuM.borrow
LIMIT 100
他にもわからないところや質問があればお気軽に連絡をください。
データの個数を数える〈COUNT〉
中級の一つ目はデータの数を数える時に使う「COUNT」を覚えましょう。
SELECT COUNT(<何を(カラム名)>) /* SELECT以外でも利用可能 */実際に先ほどののコードに加えてCOUNTを使ってみましょう。試しにLIMITを1000にして実行してみました。
SELECT COUNT(DISTINCT symbol) as token FROM compound_v2_ethereum.borrow
LIMIT 1000数を増やしてもトークンの種類は7個なことがわかりました。

COUNTと同じ場所に使うSUMも一緒に確認しておきましょう。
値を合計する〈SUM〉
SELECT SUM(<合計したいカラム名>) /* SELECT以外でも利用可能 */指定したカラムの値の合計値を出す「SUM」は合計取引量やトランザクション数の総数を知りたい時に使います。今回はこれまでのデータセットのドル建取引量に該当する「usd_amount」の合計値を計算してみましょう。
SELECT SUM(usd_amount)
FROM compound_v2_ethereum.borrow
ここで注意なのはSUMを使用すると新しいカラムが作成されるのでカラムの名前がなくなります。なので一般的にASで名前を新しく付けてあげる必要があります。今回は「total_usd_amount」にしてみましょう。その時のコードは下記のようになります。
SELECT SUM(usd_amount) AS total_usd_amount
FROM compound_v2_ethereum.borrow一方で合計数をただ確認するよりかは、日別や月別の推移を確認できた方が分析としては優れていますよね。ここから紹介する3つのことを覚えると、任意の時間軸で数値の推移を確認できるグラフを作れるようになります。
日付時間の切り捨て〈DATE_TRUNK〉
時間や日付を表す日付、時刻型のデータを任意の単位で切り捨てるために使用します。例えば「x月y日a時b分」のような時間を含むデータ「日」以降を切り捨てるとすると全てのデータが「x月y日0時0分」として扱うことができます。
DATE_TRUNK('<どこで切り捨てるか>', <何を(カラム名)>)どこで切り捨てるかはいくつかありますが、よく使うものを下にまとめました。
YEAR(年)
MONTH(月)
WEEK(週)
DAY(日)
HOUR(時間)
MINUTE(分)
SECOND(秒)
では実際に使ってみましょう。先ほどまでと同じデータセットの全てのデータを日で切り捨てて表示してみましょう。ついでに何のトークンのトランザクションかも取りましょう。その時のコードは下記のようになります。
SELECT
DATE_TRUNC('DAY', evt_block_time),
symbol AS token FROM compound_v2_ethereum.borrow取得できた結果を見てみましょう。
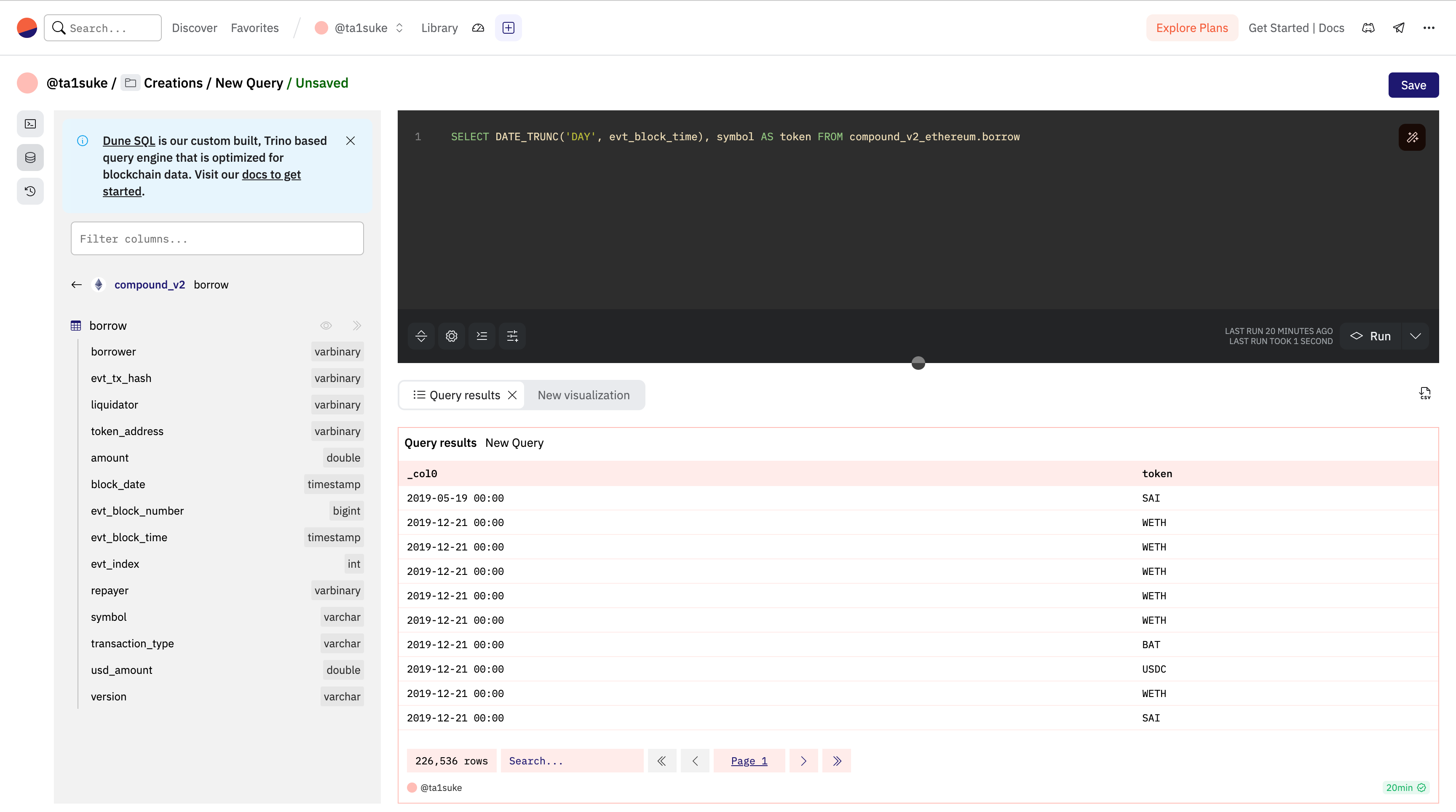
ここで注意なのはSUMと同じくDATE_TRUNKを使用するとカラムの名前がなくなります。今回は「date」にしてみましょう、その時のコードは下記のようになります。
SELECT
DATE_TRUNC('DAY', evt_block_time) AS date,
symbol AS token FROM compound_v2_ethereum.borrowデータをグループ化する〈GROUP BY〉
いちばん分析っぽいやつです。「GROUP BY」と「ORDER BY」を覚えておくだけでそれっぽいグラフを作ってdashboardにできます。
GROUP BY <何を(カラムや加工済みのカラム)>データをグループ化する「GROUP BY」は指定したカラムを重複のない形でグループ化してくれます。先ほど紹介した「DISTINCT」と近いですが、DISTINCTはSELECTとセットで使い重複行を単純に消すのに対して、「GROUP BY」はグループ化して集計を行うのに長けているので集計の場合などは私はこちらを使います。
実際に先ほどのデータをグループ化し、日毎に集計し「daily_in_outflow」という名前にしてみましょう。その時のコードは下記のようになります。
SELECT
DATE_TRUNC('DAY', evt_block_time) AS date,
SUM(usd_amount) AS daily_in_outflow
FROM compound_v2_ethereum.borrow
GROUP BY DATE_TRUNC('DAY', evt_block_time)でもこのままだと情報の時間の順番がバラバラですよね。
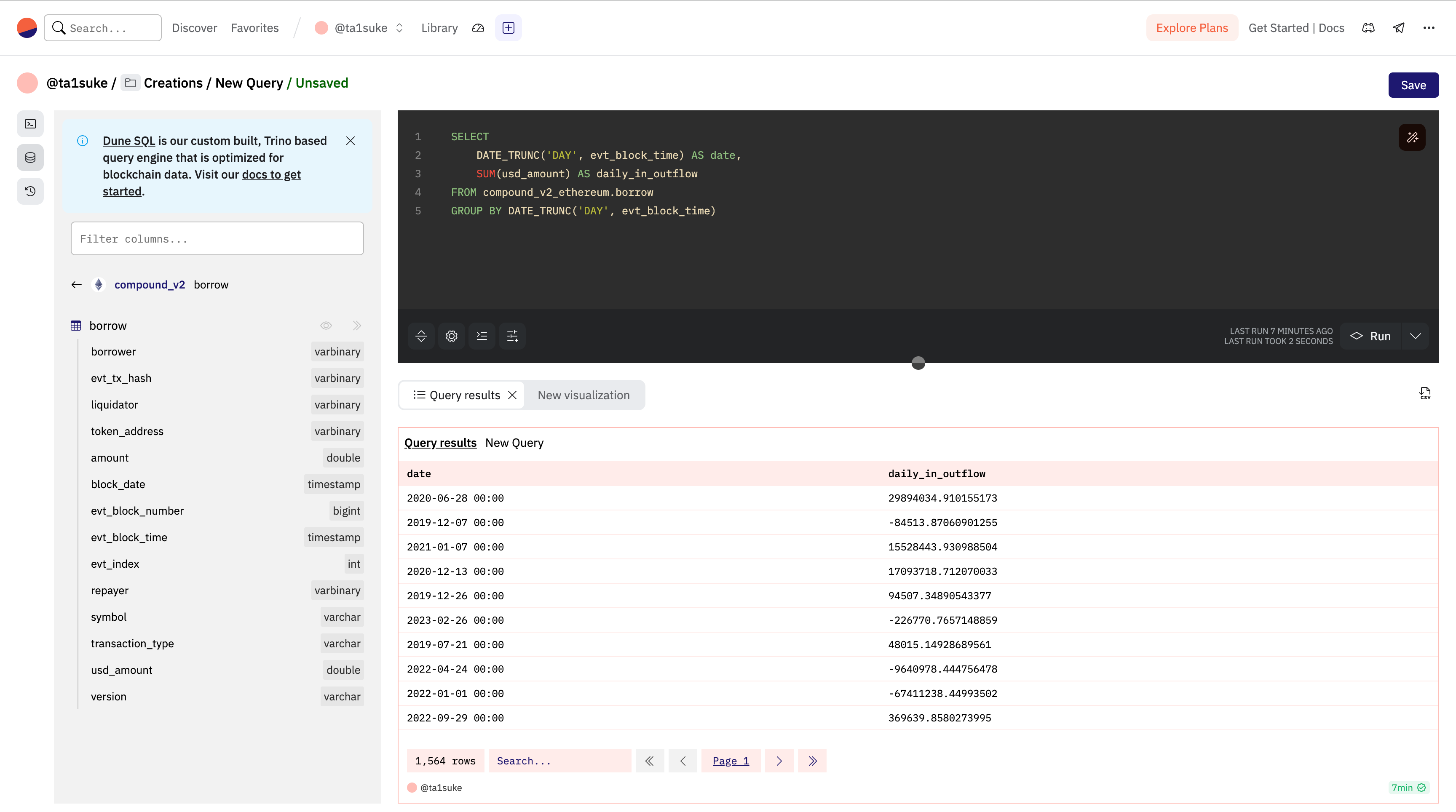
次はこれらの不規則なデータをソートして並び替えてみましょう。
データをソートする〈ORDER BY,DESC〉
データの順番を昇順、降順などでソートするためには「ORDER BY」を使います。また降順の場合は「DISC」も併用します。昇順を表す「ASC」もありますが、デフォルトで昇順になっているので省略可能です。
ORDER BY <カラム名 or 左から何番目のカラムか(id)> (asc) /* 昇順 */
ORDER BY <カラム名 or 左から何番目のカラムか(id)> desc /* 昇順 */基本的にわかりやすいようにカラム名を使用することが多いです。あと複数カラムでソートはあまり行わないので1つのqueryで1回しか使われません。
今回は新しい情報が頭に来て欲しいので「ORDER BY DESC」を使って降順でソートしてみましょう。
SELECT
DATE_TRUNC('DAY', evt_block_time) AS date,
SUM(usd_amount) AS daily_in_outflow
FROM compound_v2_ethereum.borrow
GROUP BY DATE_TRUNC('DAY', evt_block_time)
ORDER BY DATE_TRUNC('DAY', evt_block_time) DESC次に取得したこれらの情報をグラフにしてみましょう。
グラフにしてみる
データの見え方を変更するためには「New visualization」を押します。

その次の画面でどのようなデータの見え方にするかを選ぶことができます。
Bar chart(棒グラフ)
Area chart(面グラフ)
Sccatter chart(散布図)
Line chart(折れ線チャート)
Pie chart(円グラフ)
Counter(カウンター)
Table(表)
今回は推移なので相性が良さそうな「Line chart」にしてみました。

日付時間のフォーマット変更〈DATE_FORMAT〉
日付ごとに情報をまとめて並び替えるのに今回は「DATE_TRUNK」でやりましたが、似たような「DATE_FORMAT」を使うこともできます。しかも時間のフォーマットを自由に変更しながらGROUP BYを使える形にしてくれます。
DATE_FORMAT(<何を(カラム名)>, '<何に(指定されたフォーマット)>')この関数はDATE_TRUNKと同様に日付、時刻型のデータでしか使用できません。そして<何に>の部分に入るフォーマットを見ていきましょう。
%Y = 4桁の年(YYYY)
%y = 2桁の年(YY)
%M = 英語の月名(JANUARYなど)
%m = 2桁の月(MM)
%d = 2桁の日(DD)
%k = 24時間表記の時間(hh)
%i = 2桁の分(mm)
%s = 2桁の秒(ss)
いくつかの使用例を記載しておきます。
DATE_FORMAT(xxx, '%Y/%m/%d') /* YYYY/mm/dd */
DATE_FORMAT(xxx, '%k:%i') /* hh:ss */実際にDATE_TRUNKの代わりにDATE_FORMATを使って同じ結果になるqueryを作ってみましょう、今回は「YYYY/mm/dd」の形に日付のデータあを変形させましょう。その時のコードは下記のようになります。
SELECT
DATE_FORMAT(evt_block_time, '%Y/%m/%d') AS date,
SUM(usd_amount) AS daily_in_outflow
FROM compound_v2_ethereum.borrow
GROUP BY DATE_FORMAT(evt_block_time, '%Y/%m/%d')
ORDER BY DATE_FORMAT(evt_block_time, '%Y/%m/%d') DESC
値の四則演算〈+,-,*,/〉
取得した値を足す、引く、掛ける、割る、の四則演算は「+」「-」「*」「/」をそれぞれ使用することで直接計算可能です。使用時の並びは普通の計算式と同じです。
足す: +
引く: -
掛ける: *
割る: /
試しにデータセット「top_erc721_holders」の「supply_share」で取得した割合を100倍して単位を%に揃えましょう。その時のコードは下記のようになります。
SELECT
wallet_address AS Address,
balance AS Quantity,
supply_share * 100 AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
ORDER BY balance DESCsupply_shareに100をかけた結果、該当するカラムの値がきちんと100倍されています。でも小数点がいっぱい出てきちゃったので、値を四捨五入してみましょう。

値の四捨五入〈ROUND〉
カラムの数値や特定の値を四捨五入したい時はROUND関数を使用します。すごく便利な関数で四捨五入したい対象をぶち込むだけでOKです。
ROUND(<何を>) /* 1の位で四捨五入 */
ROUND(<何を>, <どこで>) 第2引数に何桁目で四捨五入したいかを指定することもできます。今回の場合は割合なので小数点第2位で四捨五入を行います。先ほどの例の時にROUNDを使って四捨五入したコードは下記のようになります。
SELECT
wallet_address AS Address,
balance AS Quantity,
ROUND(supply_share * 100, 2) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
ORDER BY balance DESC実行してみると四捨五入されていることが確認できます。

この時点でORDER BY DESCを行なっているので既に降順で上から並んでいますが、何番目のホルダーか分からないのでデータに順位をつけてみましょう。
データに順位を付ける〈RANK〉
データセットからSELECTで取得したカラムをソートして順位を付与したい場合は「RANK」を使用します。アドレスやコレクション毎の取引量ランキングやホルダーなどに順位をつけて表示したい場合にはこれを使うとかなり楽です。
また順位付けの時はソートを行なって連番を振ることが一般的なので、RANKと並べて「ORDER BY」と使うケースが多いです。
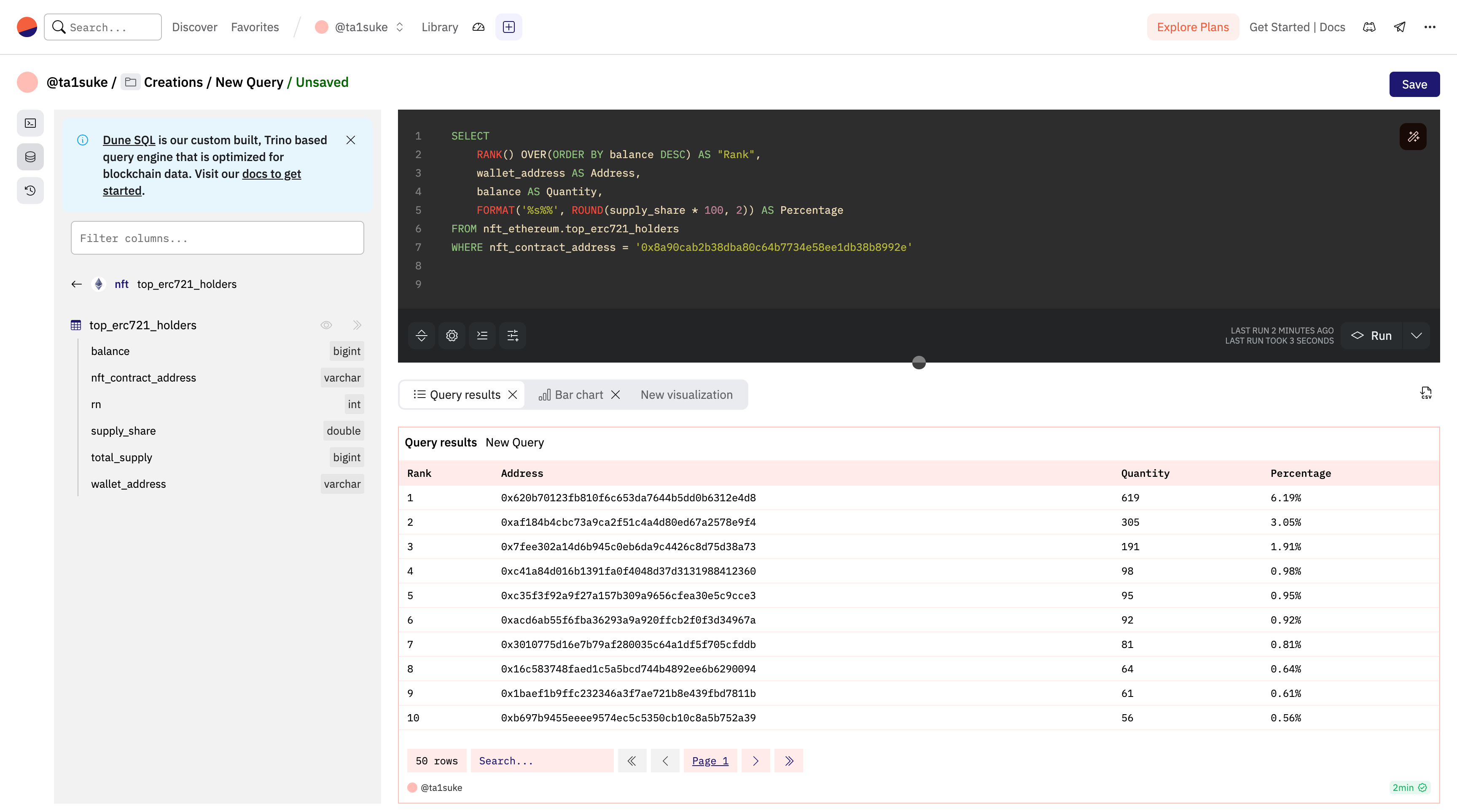
RANK() OVER(ORDER BY <何を(カラム名)> <ASC or DESC>)実際に先ほどのコードにRANKを使用してみます。下部に書いていたORDER BYは例のようにRANKとまとめられます。その時のコードは下記のようになります。
SELECT
RANK() OVER(ORDER BY balance DESC) AS "Rank",
wallet_address AS Address,
balance AS Quantity,
ROUND(supply_share * 100, 2) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'一つここで注意ポイントがあります。今回2行目でASを使って「Rank」という名前をつけていますが、関数名などですでにプログラムに組み込まれている「予約語」は区別するために「” ”」を付ける必要があります。

これにてdoodlesのホルダーランキングを作成することができました。RANKと似た挙動をする関数が2つあるので一緒に紹介しておきます。
重複順位をスキップしない〈DENSE_RANK〉
先ほど紹介した「RANK」は同率順位がくるとその個数分スキップしますが、こっちの「DENSE_RANK」は同率順位がきてもスキップしない特性があります。なのでその値自体が全体で何位かを表しているということです。
RANK: 1,2,3,4,4,4,7,7,9,10DENSE
DENSE_RANK: 1,2,3,4,4,4,5,5,6,7
DENSE_RANK() OVER(ORDER BY <何を(カラム名)> <ASC or DESC>)さっきRANKを使っていたところをDENSE_RANKに変えてみましょう。

保有枚数が重複しているところはわかりやすいですのでランキング末尾を見てみると、連続する29の次に30が来ていますよね。ここが大きな違いです。
データに連番を振る〈ROW_NUMBER〉
こちらもよく「RANK」や「DENSE_RANK」と比較されるので一緒に覚えておきましょう。ソートしたカラムに連番を振る場合は「ROW_NUMBER」を使用します。順位と異なり同率も違うものとして番号が振られます。
ROW_NUMBER() OVER(ORDER BY <カラム名> <ASC or DESC>)実際に使ってみましょう、連番になっていることは末尾の部分を確認するとわかりやすいです。50個のデータでちゃんと50番までになっています。

カラムの値を平均する〈AVG〉
上でSUMとCOUNTを覚えたと思いますが、その時に「AVG」も一緒に説明しておくべきでした。同じ使い方で指定したカラムの値の全ての平均値を返してくれる便利な関数があります。
AVG(<何を(カラム名)>)先ほどまでのdoodlesの上位50ホルダーの平均保有枚数を求めてみましょう。
SELECT
AVG(balance) AS average_balance_of_top50
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
LIMIT 50特に他の情報は必要ないので、今回は合計保有枚数のみが表示されるようにしました。
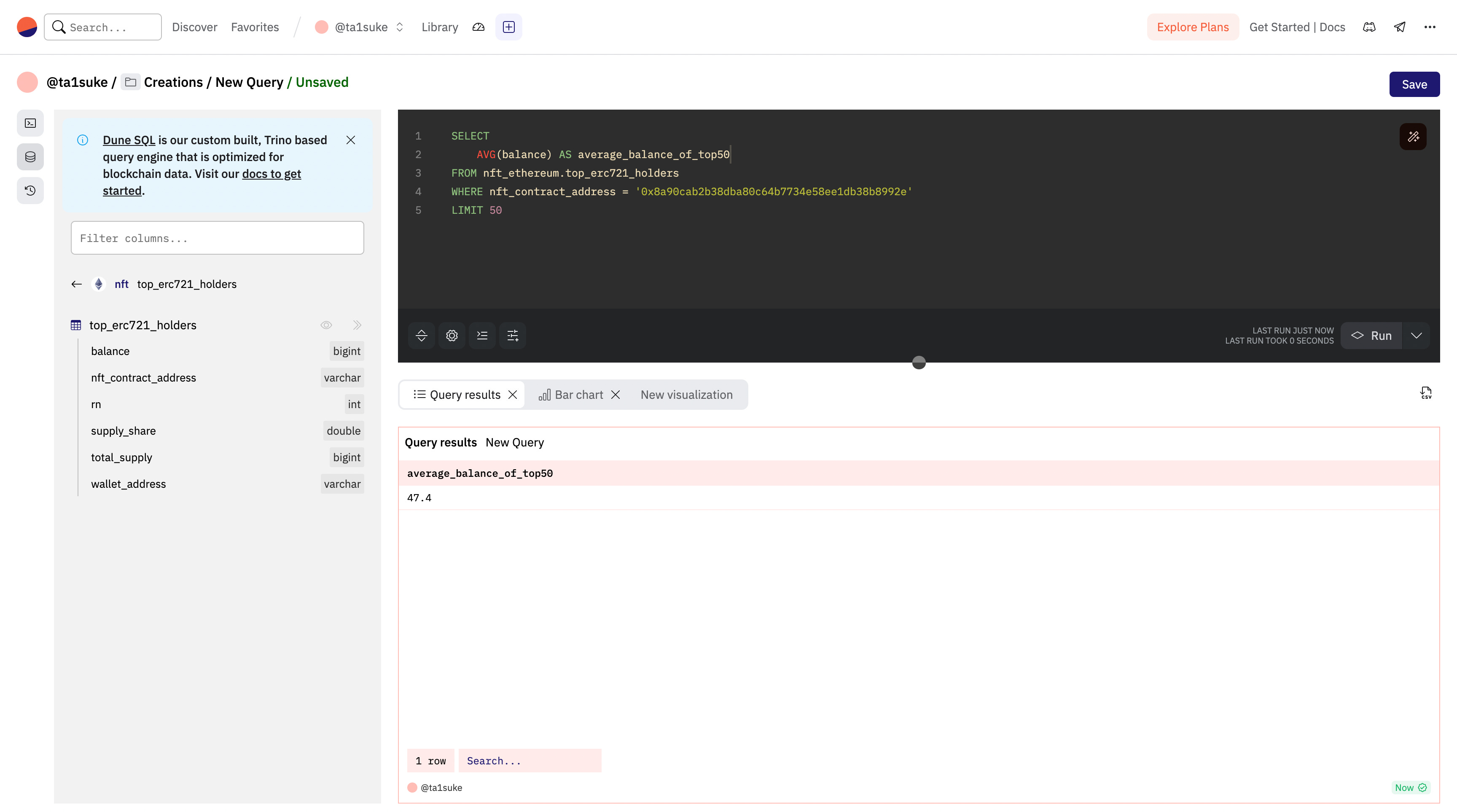
指定したフォーマットに変換〈FORMAT〉
指定したフォーマットとカラムや値を引数で渡すことで、フォーマットされた文字列を返してくれる便利な関数です。その中でもいちばん使うやつを今回は紹介して、サンプルコードにでてきたらその都度解説しますね。
SELECT format(<何に>, <何を>)
SELECT format('%s%%', <カラム、数値>) /*第2引数を%に変換*/ここで少し先ほどのホルダーリストの可読性を上げてみましょう。Percentageの各数値の後に「%」をくっつけることでみやすくしてみます。
SELECT
ROW_NUMBER() OVER(ORDER BY balance DESC) AS "Rank",
wallet_address AS Address,
balance AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'これで出力された数値に%が付くようになりました。
FORMATと同じ分類にあたる変換系の関数を2つ紹介しておきます。
値を任意の型に変換〈CAST〉
カラムの中の値を任意のデータ型に変換できる「CAST」はASを利用してデータ型の指定を行います。ここはCASTの外で使う名付けのASとは別物です。
CAST(<何を(値、カラム)> AS <何に(データ型名)>)後ほど条件分岐の部分で登場するのでそちらで詳しく紹介します。
変換失敗時にnullを返す〈TRY_CAST〉
CASTと役割は同じですが変換に失敗した時にnullを返すのが「TRY_CAST」です。
TRY_CAST(<何を(値、カラム)> AS <何に(データ型名)>)こちらも現時点ではあまり使わないので<上級>で出てきた時に詳しく解説します。
文字列を結合する〈CONCAT〉
引数に文字列を渡すことで結合させることのできる「CONCAT」は、一般的には別のカラムに保存している苗字と名前をくっつける時とかに使います。
SELECT CONCAT(<引数①>, <引数②>, <引数③>...) /* 2個以上の引数を渡す */数字同士の結合を足し算ではなく行いたい場合は、一度文字列として渡してCASTで型変換をしないと計算に再度利用することはできません。

※上記サンプルコードで利用している「TYPEOF」は引数に渡したデータの型を返してくれる関数です。エラーが出た時などのデータ型の確認にたまに利用します。
文字列の切り取り〈SUBSTRING〉
文字列の切り取りには「SUBSTRING」関数を利用します。第3引数があるかないかで挙動が変わる点に特に注意が必要です。
SELECT SUBSTRING(<何を>, <何桁目以降に>)
SELECT SUBSTRING(<何を>, <何桁目から>, <何桁目まで>)ここでは練習として先ほどのdoodlesホルダーの長くて見づらいウォレットアドレスを「0xと頭4文字+後6文字の12文字」に短縮して表示して見ましょう。
SELECT
RANK() OVER(ORDER BY balance DESC) AS "Rank",
CONCAT(SUBSTRING(wallet_address, 1, 6), '...', SUBSTRING(wallet_address, 37)) AS Address,
balance AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'ここまで答えを見ずにできたら、ある程度のダッシュボードを作るための50%の知識ぐらいまでは到達できていると思います。一旦一息付きましょう、お疲れ様です。

とは言いつつもまだまだ覚えることがあるので先に進みます。
条件分岐を〈CASE, WHEN, THEN, ELSE, END〉
条件分岐を作成してlineごとに表示する内容が変わるようにするには、「CASE」と「END」の中に条件を書くことで実現できます。条件文は「WHEN」「THEN」「ELSE」の3つを使って記述します。
CASE
WHEN <これの時(条件)> THEN <左の条件を満たしたら表示するもの>
WHEN <これの時(条件)> THEN <左の条件を満たしたら表示するもの> /* 複数条件可能 */
ELSE <どの条件を満たさなければ表示するもの>
END上の説明だとちょっとわかりづらいので、実際に上位ホルダーリストを使って条件分岐を作って見ましょう。下記の条件で表示する内容を変えてみます。
100枚以上保有: 保有枚数そのままを表示
50から99枚: 「50~99」を表示
20から49枚: 「20~49」を表示
10枚から29枚: 「10~29」を表示
9枚以下: 「~9」を表示
SELECT
RANK() OVER(ORDER BY balance DESC) AS "Rank",
CONCAT(SUBSTRING(wallet_address, 1, 6), '...', SUBSTRING(wallet_address, 37)) AS Address,
CASE
WHEN 100 <= balance THEN CAST(balance AS VARCHAR)
WHEN 50 <= balance THEN '50~99'
WHEN 20 <= balance THEN '20~49'
WHEN 10 <= balance THEN '10~29'
ELSE '~9'
END AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'ここで注意なのはCASEを使うことで表示上新たなカラムが生成されるのですが、ここには基本的に同じ型しか入れることができません。上の条件文の場合、balanceは数字ですが、他は「‘ ’」で囲っているので文字列ですよね。
なので数字を文字列に型変換する必要があります。ここで先ほど紹介したCASTを使用します。文字列に値する「VARCHAR」という型に変換してみましょう。

このようにQuantityの部分を範囲表示することに成功しました。このようにlineの値毎に表示する内容を変更したいときに条件分岐を使用します。
データ型について
ここまでの講座であまりデータ型について気にする必要はありませんでしたが、ここからはこの「型」を意識したコーディングが要所で必要になってきます。
まず普通の生活をしていたら意識することは全くないと思いますが、プログラムの世界では基本的にデータには「型」という概念が存在しています。例えば「’ ’」で囲わないといけなかった「文字列」などが型の種類です。厳密には文字列や数字の中にも言語毎にいくつかの分類があるのでそれぞれを確認してみましょう。
SQLの中にもいろんな種類があり、サービス毎に対応しているSQLの種類が違うので、今回はDuneで採用されているDune SQLに存在する一般的な型を説明しています。またDune SQL限定の型には「🏜」マークを付けています。
理論型、Boolean型
BOOLEAN: TUREかFALSEの論理演算の審議を返す
整数型、Integer(int)型
TINYINT: 1byte(8bit)までの整数を格納できる(-2^7~2^7-1)
文字数制限はできるが10進数ではなくbitの数(2進数)
SMALLINT: 2byte(16bit)までの整数を格納できる(-2^15~2^15-1)
INTEGER: 4byte(32bit)までの整数を格納できる(-2^31~2^31-1)
BIGINT: 8byte(64bit)までの整数を格納できる(-2^63~2^63-1)
🏜 UINT256: 256bitの符号なし整数を格納できる(0~2^256-1)
🏜 INT256: 256bitまでの整数を格納できる(-2^255~2^255-1)
UINT256とINT256は残高やその他の数値を表すためにEVM系スマートコントラクトで一般的に利用されているデータ型
不動小数点型、Floating-point型
REAL: IEEE754の32bitの
DOUBLE: IEEE754の64bitの
数値データ型、Fixed-precision型
DECIMAL: 2つのパラメーターからなるなる10進数の数値
DECIMAL(x, y)でxが合計桁数、yは小数点数(デフォルトは0)
文字列型、String型
VARCHAR: 長さ指定のないデータを扱う文字列
CHARのように文字列指定も可能
CHAR: 固定長のデータを扱う文字列
CHAR(x)でxに文字数を入れる(デフォルトは1)
VARBINARY: 可変長のバイナリデータを扱う文字列
Duneではaddressやhashをこの型にしている
JSON: JSONのデータ型をした文字列
日付型、Date型
DATE: ‘YYYY-MM-DD’の形で日付を扱う型
時刻型、Time型
TIME: ‘hh-mm-ss-aaa’の形で時刻を扱う型
12ピコ秒単位での小数点の秒を持つ
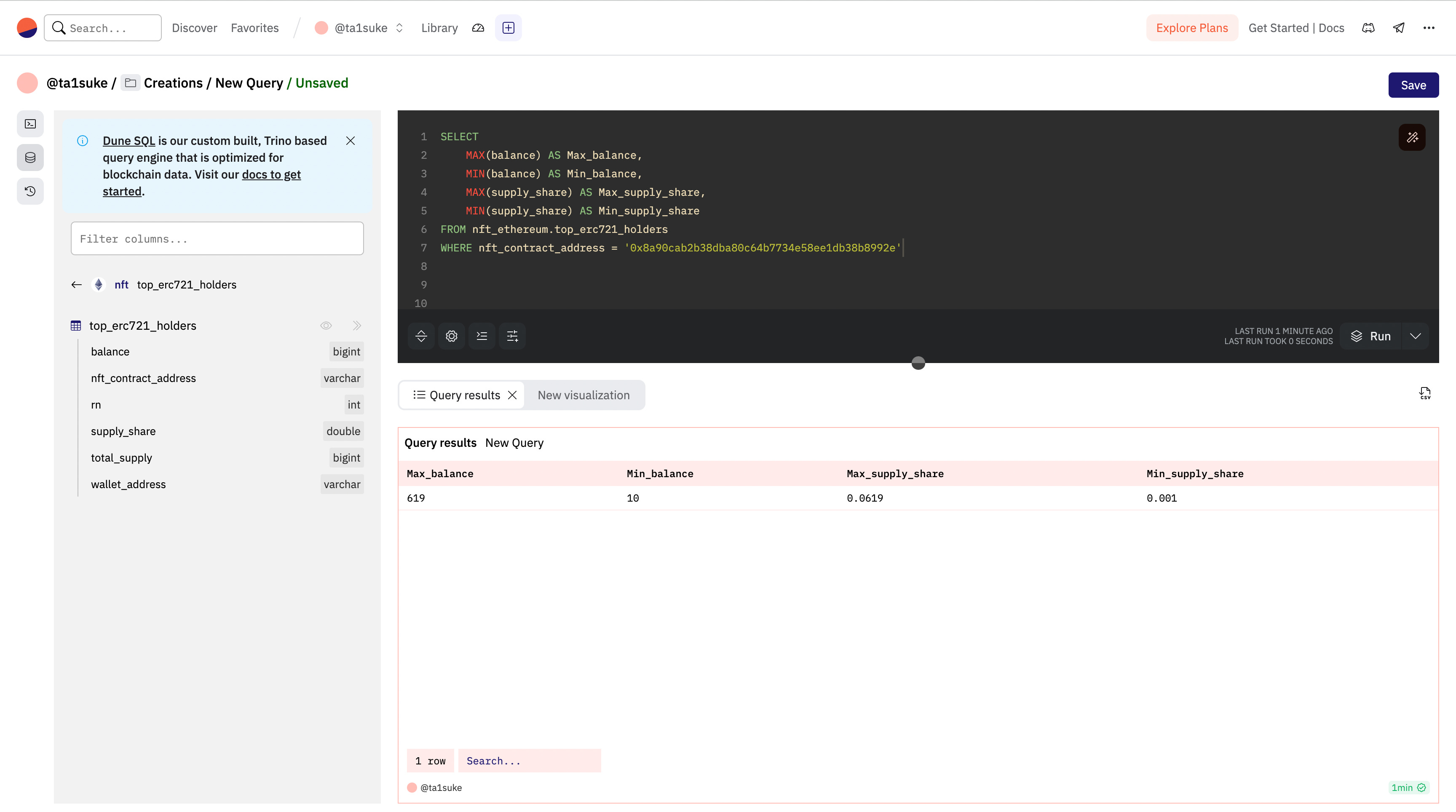
最小値と最大値を取得〈MIN, MAX〉
カラムの最小値と最大値を取得するためには「MIN」と「MAX」を利用します。それぞれ引数にカラムを渡すだけで結果を返してくれます。
MIN(<何を(カラム名)>) /* 最小値 */
MAX(<何を(カラム名)>) /* 最大値 */上での前半使用したdoodlesのホルダーリストの中から、()の名前をつけて以下を取得してみましょう。
最大保有量(Max_balance)
最小保有量(Min_balance)
最大保有率(Max_supply_share)
最小保有率(Min_supply_share)
その時のコードは下記のようになります。
SELECT
MAX(balance) AS Max_balance,
MIN(balance) AS Min_balance,
MAX(supply_share) AS Max_supply_share,
MIN(supply_share) AS Min_supply_share
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'SUMやAVG、COUNTなどと同じ簡単な使い方ですね。今回のような数値のみならず時刻型にも利用可能なので、ぜひ活用して見てください。
グループ化後に条件付与〈HAVING〉
HAVINGはWHEREと同じくデータへの条件付与を行うことができます。しかしこの2つの間では実行タイミングに大きく差があります。
HAVING <条件文>WHERE: GROUP BYより前に実行
HAVING: GROUP BYの後に実行
つまりWHEREはグループ化される前の元データに抽出条件の指定を行っていますが、HAVINGの場合がグループ化された情報に条件を指定しているということです。こちらは具体例がサンプルコードで登場したらその時に詳しく説明します。
指定範囲を取得〈BETWEEN〉
BETWEENを使うことで必要な範囲のみのデータを取得することが可能です。例えば何個目から何個目までのデータであったり、何日から何日までのデータなど。
SELECT <何を(カラム名、値)> BETWEEN <ここから> AND <ここまで>;
SELECT <何を(カラム名、値)> NOT BETWEEN <ここから> AND <ここまで>;いくつかテストコードを書いてみました。特に以上(>=)以下(<=)を利用した範囲指定は、=を右におかないといけないため可読性がかなり下がります。こういうときはBETWEENを使うとかなりわかりやすく表記できます。
SELECT 3 BETWEEN 2 AND 7 -- TRUE
/* SELECT 3 >= 2 AND 3 <= 7 と同じ意味 */
SELECT 1 BETWEEN 5 AND 11 -- FALSE
/* SELECT 1 >= 5 AND 1 <= 11 と同じ意味 */
SELECT 3 NOT BETWEEN 2 AND 7; -- FALSE
/* SELECT 3 < 2 OR 3 > 7 と同じ意味 */
SELECT 1 BETWEEN 5 AND 11 -- TRUE
/* SELECT 1 < 5 OR 11 > 5 と同じ意味 */doodles保有ランキングで以下の条件を満たすqueryを作ってみましょう。
100枚から500枚を保有するのホルダーを取得
15枚から50枚を保有していないのホルダーを取得
全体の0.2から0.5%を保有するのホルダーを取得
それぞれのコードは下記のようになります。
100枚から500枚を保有するのホルダーを取得
SELECT
ROW_NUMBER() OVER(ORDER BY balance DESC) AS "Rank",
wallet_address AS Address,
balance AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
AND balance BETWEEN 100 AND 500このように2つのアドレスのみが取得できました。

15枚から50枚を保有していないのホルダーを取得
SELECT
ROW_NUMBER() OVER(ORDER BY balance DESC) AS "Rank",
wallet_address AS Address,
balance AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
AND balance NOT BETWEEN 15 AND 5015から50枚のホルダーが排除されていることがわかりますね。

全体の0.2から0.5%を保有するのホルダーを取得
SELECT
ROW_NUMBER() OVER(ORDER BY balance DESC) AS "Rank",
wallet_address AS Address,
balance AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
AND ROUND(supply_share * 100, 2) BETWEEN 0.2 AND 0.5
-- AND supply_share BETWEEN 0.002 AND 0.005きちんと0.2から0.5%の保有率のホルダーのみが取得できました。

SQLの記述順序と実行順序
ここで少し座学的になりますが、今日はSQLの記述順序と実行順序の話に触れておきます。上級レベルになると実行順序を気にした設計も必要なのでぜひ頭に入れてもらえると嬉しいです。ちなみに<中級++>の「HAVING」がまさにそれです。
まず記述順序について見ていきましょう。記述順序に関しては結果に影響を与えないものもありますが、この順序で書いた方がいちばん速く処理されます。
SELECT → どの項目から取得するか
FROM → どのテーブルから取得するか
JOIN → テーブルの結合などの処理
WHERE → 絞り込み条件指定をする
GROUP BY → グループ化をする
HAVING → グループ化後の絞り込み条件指定をする
ORDER BY → 条件に応じて並び替えをする
LIMIT → 取得する行数を指定するか
一方で実際の処理ので記述された通りに、左上のコードから順番に行われているわけではありません。
FROM → どのテーブルから取得するか
JOIN → テーブルの結合などの処理
WHERE → 絞り込み条件指定をする
GROUP BY → グループ化をする
HAVING → グループ化後の絞り込み条件指定をする
SELECT → どの項目から取得するか
ORDER BY → 条件に応じて並び替えをする
LIMIT → 取得する行数を指定するか
このような順番で処理が行われているので、WHEREとHAVINGに違いが現れるのですね。丸暗記する必要性はもちろんないですが、頭に入れておきましょう。
並び替えて区切る〈PARTITION BY〉
SQLの中でも最近実装されたWindow関数の一つ、分析関数の「PARTITION BY」はGROUP BYと似ていてグループ化する役割を持っていますが、グループ化したものを区切って行の並び替えを行うイメージです。
なのでPARTITIONの文字の名の通り、指定された条件で行を並び替え、仕切りを作っているイメージです。なので同一の値でまとめるGROUP BYとも、RANKやROW_NUMBERとも一味違います。
PARTITION BY <何を(カラム)>しかし並び替えてグルーピングしたところでデータがソートされているわけでないので、一般的に「ORDER BY」と併用されるケースが多いです。
PARTITION BY <何を(カラム)> ORDER BY <何で(カラム名)> <何順に(ASC、DESC)>またアドレス毎にグルーピングされてもその中での優劣がわからないので、RANKやROW_NUMBERと一緒に使って順位づけを行うケースも多々あります。
RANK() OVER(PARTITION BY <何を> ORDER BY <何で> <何順に>)
ROW_NUMBER() OVER(PARTITION BY <何を> ORDER BY <何で> <何順に>)トランザクションを人ごとにまとめてランキング化するのではなく、人単位で区切ってたあとにトランザクションごとにランキングっぽくしたい場合に使えます。あまり使わないので、具体的な使用例は下のdashboard作成で出てきたら説明します。
サブクエリの可読性を向上〈WITH〉
FROMの中にSELECTとFROMをもう一回書いて新しくテーブルを作成する「サブクエリ」という記述方法がありますが、こういう場合は可読性を高めるために代替としてWITH句を使用することをオススメします。
加工済みのカラムに一時的な別の名前をつけて別で管理することで、可読性とコードのメンテナンス性を向上させることができます。
WITH <新しくつけるこのテーブル名> AS (
SELECT
<何を(カラム名)> AS <何に>,
<何を(カラム名)> AS <何に>
<何を(カラム名)> AS <何に>
FROM <参照するデータ元のテーブル名>
< WHERE や GROUP BY などの条件 >
)こちらはかなり複雑なので、PARTITION BYと同じく下のdashboard作成時に具体的な使用例を説明しようと思います。
テーブルの結合〈JOIN〉
複数のテーブル(データセットやWITH句で作成したテーブル)を単一のテーブルに結合することが可能です。「JOIN」を使って内部結合と外部結合を行えます。
JOINの中にもいくつかの種類があります。
INNER JOIN(内部結合): それどれのテーブルの一致する項目のデータを取得
OUTER JOIN(外部結合): 一方と共通する項目のデータを取得
LEFT OUTER JOIN: 左側にしかない情報も併せて取得
RIGHT OUTER JOIN: 右側にしかない情報も併せて取得
FULL OUTER JOIN: 両側どちらかしかない情報もすべて取得
CROSS JOIN(交差結合): 2つのテーブルの組み合わせをすべて取得
これらの構文を順番に説明していきたいのですが、まずテーブルの右側と左側とはなんなんでしょうか。
FROM <左側のテーブル>
JOIN <右側のテーブル>
ON <結合時の条件>それではそれぞれの構文を見ていきましょう。
INNER JOIN
JOINとINNER JOINは同じなので、INNERは省略しても大丈夫です。
SELECT <左側のテーブル> <右側のテーブル>
FROM <左側のテーブル>
(INNER) JOIN <右側のテーブル> /* INNERは省略可能 */
ON <結合時の条件>LEFT JOIN
SELECT <左側のテーブル> <右側のテーブル>
FROM <左側のテーブル>
LEFT JOIN <右側のテーブル>
ON <結合時の条件>RIGHT JOIN
SELECT <左側のテーブル> <右側のテーブル>
FROM <左側のテーブル>
RIGHT JOIN <右側のテーブル>
ON <結合時の条件>CROSS JOIN
SELECT <左側のテーブル> <右側のテーブル>
FROM <左側のテーブル>
CROSS JOIN <右側のテーブル>
ON <結合時の条件>他にもUNIONやNATURALというJOINの仲間がありますが、こちらも下でまとめて解説していきます!お疲れ様です、これにて学習部分の講座は一通り終了です。
ダッシュボードについて
Duneのdashboardとは作成した複数のqueryを1つにまとめて表示できる場所のことを指します。実際にオンチェーン分析を行った結果をquery単体で公開するわけではなくて、queryをさらにdashboardでまとめて公開します。
今回のゴールの完成品はこちら↓

リンク: friend.tech and base activity
↑受講した方はぜひスターを付けに行ってもらえると嬉しいです。
dashboardはqueryの新規作成と同じ「+」ボタンから作成できます。今回の講座ではすべてのqueryが作成し終わってからdashboardを作るので、まずは一緒にそれぞれのqueryを作っていきましょう!
※また要所で復習可能なように該当する構文を説明している講座リンクを適宜貼っています。わからないところは都度復習して習得していきましょう。
合計トランザクション数を取得しよう
まずはfriend.techを利用している人たちの合計トランザクション数を計測してみましょう。そのためにdocsかexplorerからfriend.techのcontractを探す必要があります。
friend.techのcontractを探す
Baseのtxが取得できるDuneのデータセットを探す
最適なvisualizationにして表示する
friend.techのcontractはBaseのexplorer「BaseScan」で検索してみると出てきました
0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4次にBaseのtxが取得できるDuneのデータセットを探しましょう。データセットの名前から推測ができたとしても一旦「SELECT * FROM <データセット名>」を少なめのLIMITで試しに全カラムを取ってデータの中身を確認してみましょう。
今回は「base.transactions」を使って取得してみましょう。
SELECT
COUNT(block_time) AS All_tx_counts
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)注意ポイントをいくつかまとめてみました。
「to」が予約語なので「”to”」にする必要がある
「to」のカラムの型が「VARBINARY」なので比較先も「VARBINARY」へ変換
どのtxでも値が存在するblock_timeの数をカウント

tx数は集計したタイミングによって異なるので「BaseScan Friend.tech: Shares」を見てみなさんが受講した時の数字とほぼ一致していたら問題ないです。
次にこのqueryのvisualizationを最適なものにして表示してみましょう。COUNTやAVGなどで取ってきた数値は単一なので「Counter」を使いましょう。
合計ユーザー数を取得しよう
次にfriend.techの合計ユーザー数を取得してみましょう。
ユーザー数の判定方法はcontractを見て行います。friend.techの場合はShareを買うときも売るときも同一のcontractを叩くので、contract側がfromに入ることはありません。よってユーザー側が絶対にfromに入ります。
fromでアドレスをグループ化して、ユニークなアドレスの数をCOUNTで求めるることで取得することができます。
SELECT
COUNT(DISTINCT("from")) AS count_txs
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)COUNT内でGROUP BYが使用できないので、「DISTINCT」を使用している点がここの注意ポイントです。こちらもvisualizationはCOUNTにします。
〇Duneの画像〇
今日のアクティブウォレット数を取得しよう
今日のアクティブウォレットを取得するための「今日」のデータはどうやって条件指定するのでしょうか?
まず今の時間をTIMESTAMP型で取得できる「NOW」という関数があります。今回はこれを利用しましょう。
DATE_TRUNCを利用して日時を丸めるので、なのでNOWにもDATE_TRUNCをかけて同じ形にし、WHEREで探せば今日のアクティブウォレットが取得できます。
SELECT
COUNT("from") AS active_wallet
FROM base.transactions
WHERE DATE_TRUNC('day', block_time) = DATE_TRUNC('day',NOW())
GROUP BY DATE_TRUNC('day', block_time)
ORDER BY DATE_TRUNC('day', block_time) DESCfriend.techの今日のアクティブウォレットも取得してみましょう。
SELECT
COUNT("from") AS active_wallet
FROM base.transactions
WHERE DATE_TRUNC('day', block_time) = DATE_TRUNC('day',NOW())
AND "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
GROUP BY DATE_TRUNC('day', block_time)
ORDER BY DATE_TRUNC('day', block_time) DESCこのように今日や昨日といった固定の特定日ではなく、毎日変更する値を取るためには「NOW」を活用することを覚えておいてください。後半にも登場します。
Baseのtx数の推移と比較しよう
次にBaseの日間トランザクション数との比較を行いましょう。またfriend.techのトランザクション数がBaseの何%を占めているかも計算しましょう。
Baseのtx数を日別で取得
friend.techのtx数を日別で取得
friend.tech tx / Base tx を求める
2つのテーブルを結合させる
最適なvisualizationにして表示する
まずBaseのtx数を日別で取得して別々のテーブルにする必要があるので、今回はテーブル作成の部分に「WITH句」を使います。またテーブルの結合には「JOIN」を使います。実際の使い方から2つの構文を覚えていきましょう。
テーブル: BASEのトランザクション
カラム: BASEの日付
カラム: BASEのトランザクション
テーブル: friend.techのトランザクション
カラム: friend.techの日付
カラム: friend.techのトランザクション
それぞれが完成したコードが下記のようになります。カラム名は自由なものを付けて大丈夫です。
WITH
base_daily_tx AS (
SELECT
DATE_TRUNC('day', block_time) AS b_date,
COUNT(block_time) AS b_daily_tx
FROM base.transactions
GROUP BY DATE_TRUNC('day', block_time)
),
ft_daily_tx AS (
SELECT
DATE_TRUNC('day', block_time) AS f_date,
COUNT(block_time) AS f_daily_tx
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
GROUP BY DATE_TRUNC('day', block_time)
)次にWITH句で作成したテーブルをJOIN句で結合しましょう。friend.techよりBaseの方が前からあるので、2つのテーブルのblock_timeが一致するところでまとめて下記の3つのカラムになるようにしましょう。
日付(block_time)
ORDER BY DESC で降順に並べ替え
Baseの日別tx数
friend.techの日別tx数
では早速やってみましょう、その時のコードは下記のようになります。
SELECT
b_date AS "Date",
b_daily_tx AS Base_txs,
f_daily_tx AS "friend.tech_txs",
FROM base_daily_tx
JOIN ft_daily_tx
ON base_daily_tx.b_date = ft_daily_tx.f_date
ORDER BY b_date DESC四則演算はそのまま記述して大丈夫で、他のカラムと同様に日別で表示してあげたいのでSELECT内にまずは計算式をいれましょう。
f_daily_tx / b_daily_txしかしこのままだと計算できないのでそれぞれを「DOUBLE」に型変換しましょう。
CAST(f_daily_tx AS DOUBLE) / CAST(b_daily_tx AS DOUBLE)これで計算はできましたが、100%が1で表示されていることに加え、小数点以下の桁数がめちゃくちゃ多いので小数点第二位で四捨五入をしてみましょう。
ROUND(CAST(f_daily_tx AS DOUBLE) / CAST(b_daily_tx AS DOUBLE) * 100, 2)最後にFORMATを使って末尾に「%」を付けましょう。
FORMAT('%s%%', ROUND(CAST(f_daily_tx AS DOUBLE) / CAST(b_daily_tx AS DOUBLE) * 100, 2)) AS "Percentage of friend.tech"これにて取得完了です、最後に全てのコードを貼っておきます。
WITH
base_daily_tx AS (
SELECT
DATE_TRUNC('day', block_time) AS b_date,
COUNT(block_time) AS b_daily_tx
FROM base.transactions
GROUP BY DATE_TRUNC('day', block_time)
),
ft_daily_tx AS (
SELECT
DATE_TRUNC('day', block_time) AS f_date,
COUNT(block_time) AS f_daily_tx
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
GROUP BY DATE_TRUNC('day', block_time)
)
SELECT
b_date AS "Date",
b_daily_tx AS Base_txs,
f_daily_tx AS "friend.tech_txs",
FORMAT('%s%%', ROUND(CAST(f_daily_tx AS DOUBLE) / CAST(b_daily_tx AS DOUBLE) * 100, 2)) AS "Percentage of friend.tech"
FROM base_daily_tx
JOIN ft_daily_tx
ON base_daily_tx.b_date = ft_daily_tx.f_date
ORDER BY b_date DESC次に取得したデータからvisualizationを作成してみましょう。今回のような複数のカラムの推移を比較したい場合は、「Line chart」を使うのがオススメです。

グラフ下部の「Result data」から表示する内容を変更できます。今回はすべてのカラムを日別で表示したいので、X軸に「date」、Y軸に3つのカラムを指定しましょう。
これでBaseのtx数の推移と比較は完了です、次のquery作成に進みましょう。
日別アクティブアドレス数の推移を取得しよう
次に日別のアクティブアドレス数(DAU)をBaseとfriend.techのそれぞれで調べてみましょう。そして推移のグラフを作成します。
Baseのユニークアドレス数を日別で取得
friend.techのユニークアドレス数を日別で取得
friend.tech / Base ユニークアドレスを求める
2つのテーブルを結合させる
最適なvisualizationにして表示する
先程の応用なので説明は省略します、その時のコードは下記のようになります。
WITH
base_account_counts AS (
SELECT
DATE_TRUNC('day', block_time) AS b_date,
COUNT(DISTINCT("from")) AS b_count_acs
FROM base.transactions
GROUP BY DATE_TRUNC('day', block_time)
),
ft_account_counts AS (
SELECT
DATE_TRUNC('day', block_time) AS f_date,
COUNT(DISTINCT("from")) AS f_count_acs
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
GROUP BY DATE_TRUNC('day', block_time)
)
SELECT
b_date AS "Date",
b_count_acs AS Base_acs,
f_count_acs AS "friend.tech_acs",
FORMAT('%s%%', ROUND(CAST(f_count_acs AS DOUBLE) / CAST(b_count_acs AS DOUBLE) * 100, 2)) AS "Percentage of friend.tech"
FROM base_account_counts
JOIN ft_account_counts
ON base_account_counts.b_date = ft_account_counts.f_date
ORDER BY b_date DESCアドレス毎のtx数をランキングにしよう
ここではfriend.techを利用しているアドレスの中でトランザクションが多い順に並べてランキングにしてみましょう。新規登録ユーザーのShareをすぐに買うBOTがいるみたいなのでこれで探すとaddressの特定ができるかもしれません。
fromでグループ化してCOUNTで集計
集計した数にRANKで順位を付ける
その時のコードは下記のようになります。
SELECT
RANK() OVER(ORDER BY COUNT(block_time) DESC) AS Ranking,
"from" AS address,
COUNT(block_time) AS trades
FROM base.transactions
WHERE "to" = 0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4
GROUP BY "from"Shareの最高取引額からランキングにしよう
friend.techのShareは高いものだといくらで取引されているんでしょうか?1txの取引額で高かったものから順にランキングにしてみましょう。
RANKで順位を付ける
valueが小数点のない値なのでETHのdecimalを考慮して10の18乗倍する
今回新しく登場する「POWER」について説明します。
POWER(<何の><何乗倍に>)実際にPOWERを使って作成したqueryはこちら。
SELECT
RANK() OVER(ORDER BY value DESC) AS Ranking,
"from" AS address,
CONCAT(CAST(ROUND(value / POWER(10, 18), 4) AS VARCHAR), 'Ξ') AS volume
FROM base.transactions
WHERE "to" = 0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4前日と比較した今日のtxの増加数を調べよう
いちばん最難関のquery作成を最後の2つに詰め込みました。前日までのデータと現時点のデータを比較して前日からの増加量を調べます。
それぞれのテーブルを作成
テーブルを結合させる
「- interval '1' day」で一日遡らせる
まずは今日の現時点までのデータを取得してみましょう。テーブルを新たに作成するのでWITH句を使用します。
WITH ft_count_today AS(
SELECT
COUNT("from") AS today_count
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
AND DATE_TRUNC('day', block_time) <= DATE_TRUNC('day', NOW())
)次に一日前までのデータを取得しましょう。ここでは日時型に対して「interval」で指定した値を足し引きできる仕組みを使用します。
ft_count_yesterday AS(
SELECT
COUNT("from") AS yeseterday_count
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
AND DATE_TRUNC('day', block_time) <= DATE_TRUNC('day', NOW()) - interval '1' day
)次にこれらの2つのテーブルを結合させましょう。CROSS JOINで交差結合させ、同一の行に2つのデータが並ぶようにしました。
unit_count AS(
SELECT
today_count,
ft_count_yesterday.yeseterday_count
FROM ft_count_today
CROSS JOIN ft_count_yesterday
)最後に結合させてできた行をもとに、計算を行いましょう。
SELECT
FORMAT('%s%%' ,ROUND((CAST(today_count AS DOUBLE) - CAST(yeseterday_count AS DOUBLE)) / CAST(yeseterday_count AS DOUBLE)*100, 3)) AS ratio
FROM unit_countすべてのコードもこちらに貼っておきます。
WITH ft_count_today AS(
SELECT
COUNT("from") AS today_count
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
AND DATE_TRUNC('day', block_time) <= DATE_TRUNC('day', NOW())
),
ft_count_yesterday AS(
SELECT
COUNT("from") AS yeseterday_count
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
AND DATE_TRUNC('day', block_time) <= DATE_TRUNC('day', NOW()) - interval '1' day
),
unit_count AS(
SELECT
today_count,
ft_count_yesterday.yeseterday_count
FROM ft_count_today
CROSS JOIN ft_count_yesterday
)
SELECT
FORMAT('%s%%' ,ROUND((CAST(today_count AS DOUBLE) - CAST(yeseterday_count AS DOUBLE)) / CAST(yeseterday_count AS DOUBLE)*100, 3)) AS ratio
FROM unit_count前日と比較した今日のアクティブアドレスの増加数を調べよう
先程は全てのtxを数えていましたが、fromのアドレスをグループ化して集計を行います。なのである2箇所にあの文言を足すだけで完了します。
答えは「DISTINCT」です、場所は下のコードを確認してください。
WITH ft_count_today AS(
SELECT
COUNT(DISTINCT "from") AS today_count
FROM
base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
AND DATE_TRUNC('day', block_time) <= DATE_TRUNC('day', NOW())
),
ft_count_yesterday AS(
SELECT
COUNT(DISTINCT "from") AS yeseterday_count
FROM base.transactions
WHERE "to" = CAST(0xCF205808Ed36593aa40a44F10c7f7C2F67d4A4d4 AS VARBINARY)
AND DATE_TRUNC('day', block_time) <= DATE_TRUNC('day', NOW()) - interval '1' day
),
unit_count AS(
SELECT
today_count,
ft_count_yesterday.yeseterday_count
FROM ft_count_today
CROSS JOIN ft_count_yesterday
)
SELECT
FORMAT('%s%%' ,ROUND((CAST(today_count AS DOUBLE) - CAST(yeseterday_count AS DOUBLE)) / CAST(yeseterday_count AS DOUBLE)*100, 3)) AS ratio
FROM unit_countdashboardを作成しよう
すべてのqueryが作り終えたので自分だけのdashboardを作成しましょう。最初に紹介したところから新規dashboardを作成してください。

そして右上の「Edit」から「Add visualization」を押すと、作成したqueryがタイルで配置できます。配置は皆さんのセンスにおまかせします!ちなみに自分は最初に貼りましたがこうなりました↓
リンク: friend.tech and base activity
↑受講した方はぜひスターを付けに行ってもらえると嬉しいです。
ぜひここまで完了した方はdashboardのリンクを私のX!に共有いただけますと非常に嬉しいです!すぐスター押しに行きます!!!
さいごに
最後まで見ていただきましてありがとうございました。既に2,000人以上の方にDune講座を読んでいただき、Twitterのインプレッションも合計5万を超えています。
実際にこの講座を通じて手を動かしてくれている方が多くいて、たくさんの方にオンチェーン分析の魅力が伝わって本当に嬉しいです!
引き続き日本ではDuneを知ってもらうための活動をしていこうと思うので、これからもみなさんのonchain lifeを少しでもいいものにできればと思います!メールアドレスの登録がまだの方はぜひよろしくお願いします!