
[8.19] 形で覚えるDune使い方講座<中級>
実用的なDuneの文法をしっかり覚えよう

みなさん昨日までのDune講座<初級>と<初級+>を見ていただいてありがとうございます。たくさんの方に見ていただけて本当に嬉しいです、今日からは中級ということで少し難しくなりますが、誰しも初めはできなかったので頑張って習得しましょう!
前回までの講座をまだみていない方はこちらから↓
![[8.17] 形で覚えるDune使い方講座<初級>](https://substackcdn.com/image/fetch/$s_!_i02!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd3e74bdc-c5b2-4bf0-8859-e2c1f32dc5a3_1728x963.png)
![[8.18] 形で覚えるDune使い方講座<初級+>](https://substackcdn.com/image/fetch/$s_!-i8Q!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F523f618f-b99c-4d17-a903-53fb8aa1ef53_3456x1926.png)
今回は<中級>編、データの数を数えたり、値を合計したり、切り捨て、グループ化、並び替えなどを経てグラフ作成の方法まで解説します。なんかDuneっていうよりもうSQL講座に近くなってきましたね。
一気に進むのでぜひこの日曜日を活用して学習していきましょう。
Special thanks to @Guss3.eth and @hideyukiaka
※コードブロックを使用して説明しているため、なるべくパソコンからのアクセスをお勧めします。またこの講座を受けるためにはパソコンが必要です。
みんなの質問回答
いくつかみなさんから質問がありましたのでそれに回答していきます。
サンプルコードと違う位置で改行してもいいですか?
もちろん大丈夫です。改行自体はコードの実行内容に影響を与えないので、自分の視認性が上がるところで改行して問題ないです。
ASの後に「’ ’」を使わないのはなぜですか?
ASの後に入力する任意の名前は文字列ではなく、カラム名のため「’ ’」を使用しません。カラム名に一時的(実行するコード内のみで有効)なニックネームをつけるみたいな。エンジニア向けの説明をするとエイリアスです。
大文字小文字を区別しますか?
大文字と小文字によって実行結果に差異は生じません。試しに下記のようにカラム名やデータセットの名前を不規則に大文字へ変更してみましたが、きちんと実行できました。視認性の問題なので自分の中でルールを決めて書くのがいいでしょう。基本的にカラム名をわざわざ大文字に直す必要ないのでそのまま使いましょう。
SELECT bOrrower, evt_bLock_timE FROM compound_v2_EthereuM.borrow
LIMIT 100
他にもわからないところや質問があればお気軽に連絡をください。
データの個数を数える〈COUNT〉
中級の一つ目はデータの数を数える時に使う「COUNT」を覚えましょう。
SELECT COUNT(<何を(カラム名)>) /* SELECT以外でも利用可能 */実際に昨日のコードに加えてCOUNTを使ってみましょう。試しにLIMITを1000にして実行してみました。
SELECT COUNT(DISTINCT symbol) as token FROM compound_v2_ethereum.borrow
LIMIT 1000数を増やしてもトークンの種類は7個なことがわかりました。

COUNTと同じ場所に使うSUMも一緒に確認しておきましょう。
値を合計する〈SUM〉
SELECT SUM(<合計したいカラム名>) /* SELECT以外でも利用可能 */指定したカラムの値の合計値を出す「SUM」は合計取引量やトランザクション数の総数を知りたい時に使います。今回はこれまでのデータセットのドル建取引量に該当する「usd_amount」の合計値を計算してみましょう。
SELECT SUM(usd_amount)
FROM compound_v2_ethereum.borrow
ここで注意なのはSUMを使用すると新しいカラムが作成されるのでカラムの名前がなくなります。なので一般的にASで名前を新しく付けてあげる必要があります。今回は「total_usd_amount」にしてみましょう。その時のコードは下記のようになります。
SELECT SUM(usd_amount) AS total_usd_amount
FROM compound_v2_ethereum.borrow一方で合計数をただ確認するよりかは、日別や月別の推移を確認できた方が分析としては優れていますよね。ここから紹介する3つのことを覚えると、任意の時間軸で数値の推移を確認できるグラフを作れるようになります。
日付時間の切り捨て〈DATE_TRUNK〉
時間や日付を表す日付、時刻型のデータを任意の単位で切り捨てるために使用します。例えば「x月y日a時b分」のような時間を含むデータ「日」以降を切り捨てるとすると全てのデータが「x月y日0時0分」として扱うことができます。
DATE_TRUNK('<どこで切り捨てるか>', <何を(カラム名)>)どこで切り捨てるかはいくつかありますが、よく使うものを下にまとめました。
YEAR(年)
MONTH(月)
WEEK(週)
DAY(日)
HOUR(時間)
MINUTE(分)
SECOND(秒)
では実際に使ってみましょう。先ほどまでと同じデータセットの全てのデータを日で切り捨てて表示してみましょう。ついでに何のトークンのトランザクションかも取りましょう。その時のコードは下記のようになります。
SELECT
DATE_TRUNC('DAY', evt_block_time),
symbol AS token FROM compound_v2_ethereum.borrow取得できた結果を見てみましょう。
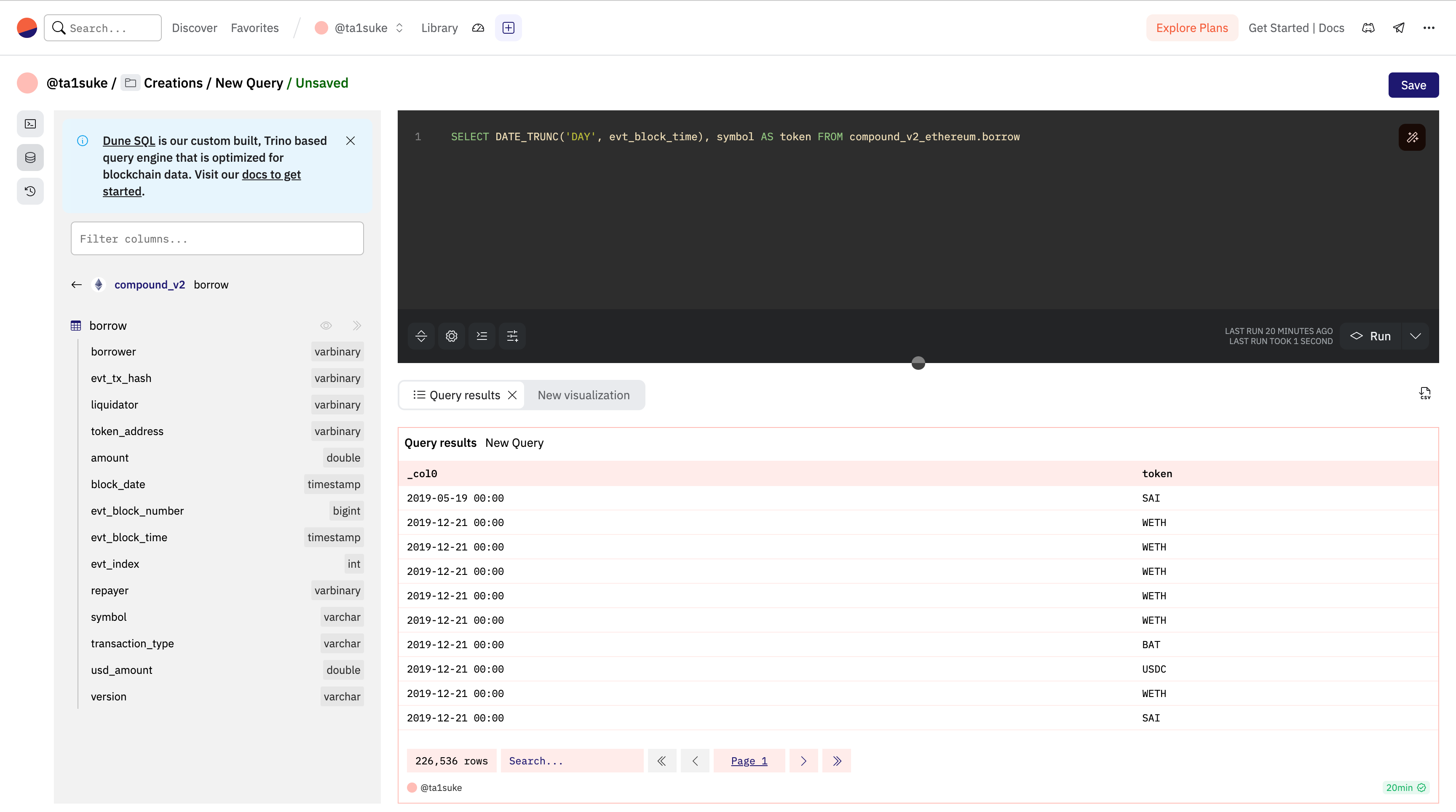
ここで注意なのはSUMと同じくDATE_TRUNKを使用するとカラムの名前がなくなります。今回は「date」にしてみましょう、その時のコードは下記のようになります。
SELECT
DATE_TRUNC('DAY', evt_block_time) AS date,
symbol AS token FROM compound_v2_ethereum.borrowデータをグループ化する〈GROUP BY〉
いちばん分析っぽいやつです。「GROUP BY」と「ORDER BY」を覚えておくだけでそれっぽいグラフを作ってdashboardにできます。
GROUP BY <何を(カラムや加工済みのカラム)>データをグループ化する「GROUP BY」は指定したカラムを重複のない形でグループ化してくれます。昨日紹介した「DISTINCT」と近いですが、DISTINCTはSELECTとセットで使い重複行を単純に消すのに対して、「GROUP BY」はグループ化して集計を行うのに長けているので集計の場合などは私はこちらを使います。
実際に先ほどのデータをグループ化し、日毎に集計し「daily_in_outflow」という名前にしてみましょう。その時のコードは下記のようになります。
SELECT
DATE_TRUNC('DAY', evt_block_time) AS date,
SUM(usd_amount) AS daily_in_outflow
FROM compound_v2_ethereum.borrow
GROUP BY DATE_TRUNC('DAY', evt_block_time)でもこのままだと情報の時間の順番がバラバラですよね。
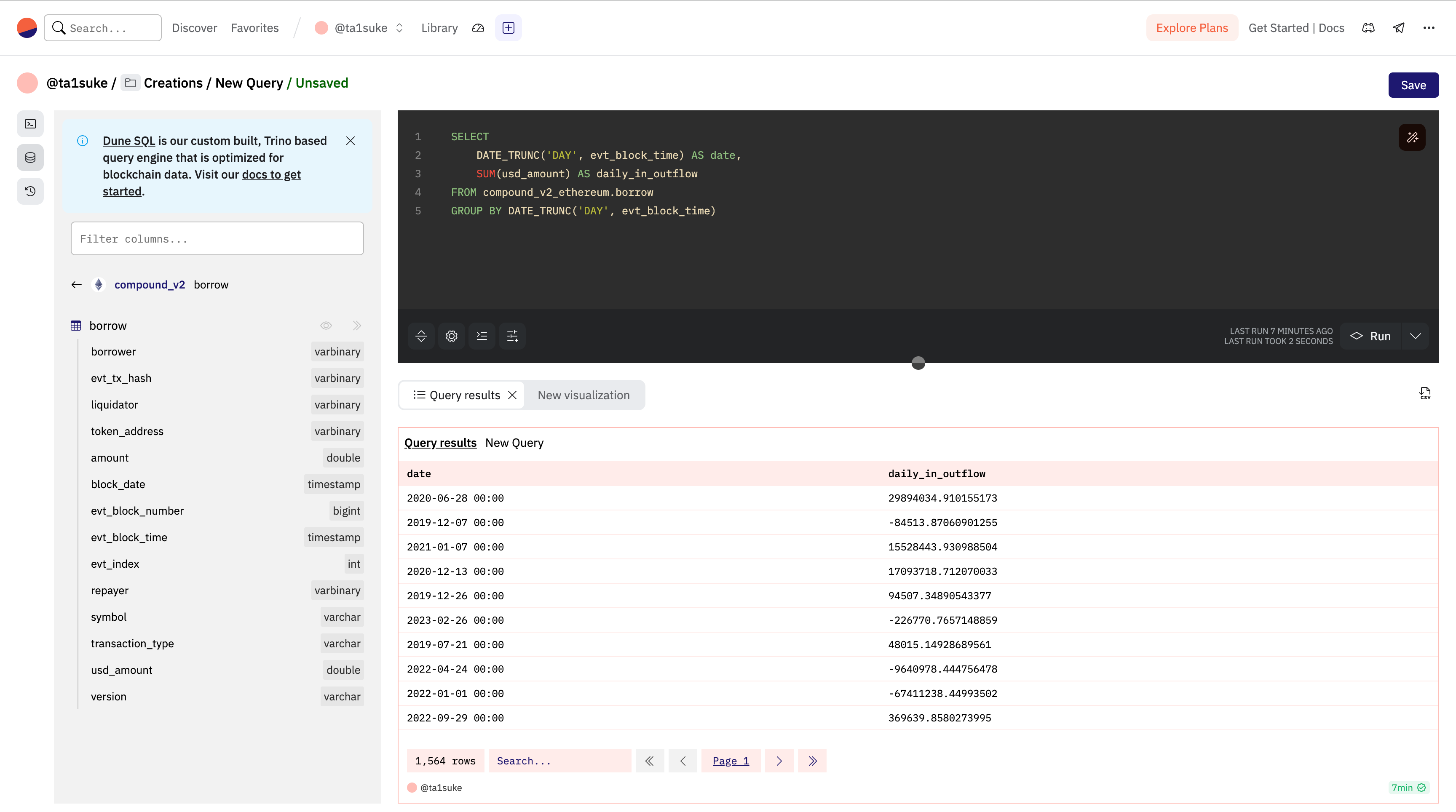
次はこれらの不規則なデータをソートして並び替えてみましょう。
データをソートする〈ORDER BY,DESC〉
データの順番を昇順、降順などでソートするためには「ORDER BY」を使います。また降順の場合は「DISC」も併用します。昇順を表す「ASC」もありますが、デフォルトで昇順になっているので省略可能です。
ORDER BY <カラム名 or 左から何番目のカラムか(id)> (asc) /* 昇順 */
ORDER BY <カラム名 or 左から何番目のカラムか(id)> desc /* 昇順 */基本的にわかりやすいようにカラム名を使用することが多いです。あと複数カラムでソートはあまり行わないので1つのqueryで1回しか使われません。
今回は新しい情報が頭に来て欲しいので「ORDER BY DESC」を使って降順でソートしてみましょう。
SELECT
DATE_TRUNC('DAY', evt_block_time) AS date,
SUM(usd_amount) AS daily_in_outflow
FROM compound_v2_ethereum.borrow
GROUP BY DATE_TRUNC('DAY', evt_block_time)
ORDER BY DATE_TRUNC('DAY', evt_block_time) DESC次に取得したこれらの情報をグラフにしてみましょう。
グラフにしてみる
データの見え方を変更するためには「New visualization」を押します。

その次の画面でどのようなデータの見え方にするかを選ぶことができます。
Bar chart(棒グラフ)
Area chart(面グラフ)
Sccatter chart(散布図)
Line chart(折れ線チャート)
Pie chart(円グラフ)
Counter(カウンター)
Table(表)
今回は推移なので相性が良さそうな「Line chart」にしてみました。

日付時間のフォーマット変更〈DATE_FORMAT〉
日付ごとに情報をまとめて並び替えるのに今回は「DATE_TRUNK」でやりましたが、似たような「DATE_FORMAT」を使うこともできます。しかも時間のフォーマットを自由に変更しながらGROUP BYを使える形にしてくれます。
DATE_FORMAT(<何を(カラム名)>, '<何に(指定されたフォーマット)>')この関数はDATE_TRUNKと同様に日付、時刻型のデータでしか使用できません。そして<何に>の部分に入るフォーマットを見ていきましょう。
%Y = 4桁の年(YYYY)
%y = 2桁の年(YY)
%M = 英語の月名(JANUARYなど)
%m = 2桁の月(MM)
%d = 2桁の日(DD)
%k = 24時間表記の時間(hh)
%i = 2桁の分(mm)
%s = 2桁の秒(ss)
いくつかの使用例を記載しておきます。
DATE_FORMAT(xxx, '%Y/%m/%d') /* YYYY/mm/dd */
DATE_FORMAT(xxx, '%k:%i') /* hh:ss */実際にDATE_TRUNKの代わりにDATE_FORMATを使って同じ結果になるqueryを作ってみましょう、今回は「YYYY/mm/dd」の形に日付のデータあを変形させましょう。その時のコードは下記のようになります。
SELECT
DATE_FORMAT(evt_block_time, '%Y/%m/%d') AS date,
SUM(usd_amount) AS daily_in_outflow
FROM compound_v2_ethereum.borrow
GROUP BY DATE_FORMAT(evt_block_time, '%Y/%m/%d')
ORDER BY DATE_FORMAT(evt_block_time, '%Y/%m/%d') DESCみなさんここまでついて来れているでしょうか?今日はこのぐらいにしておいて、明日に<中級+>として続きを紹介したいと思います。

まとめ
少しここら辺から難しくなってきましたね。エンジニアであればまだまだ全然簡単だと思いますが、非エンジニアの方はそろそろ難しくなってくると思います。
明日はサブクエリの作成やMIN、MAXの説明、その他重要な関数と、ダッシュボードの作成部分までいけたらと思います。みなさんぜひ最後までついてきてください!一緒に頑張りましょう!
この講座から1人でも多くオンチェーン分析に興味を持ってDuneユーザーが増えると嬉しいです。
次のレベルのDune講座はこちらから↓
![[8.20] 形で覚えるDune使い方講座<中級+>](https://substackcdn.com/image/fetch/$s_!hGFA!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa9c54345-03ce-451b-908c-c8d3648ca31d_3456x1926.png)