
[8.20] 形で覚えるDune使い方講座<中級+>
ここまで来れたらDuneマスターまでもう一歩

みなさん昨日までの<中級>Dune講座を見ていただいてありがとうございます。たくさんの方に見ていただけて本当に嬉しいです、明日から上級編に入るための大事なステップなので少し分量が多いですがみなさん一緒に頑張りましょう。
前回までの講座をまだみていない方はこちらから↓
![[8.17] 形で覚えるDune使い方講座<初級>](https://substackcdn.com/image/fetch/$s_!_i02!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd3e74bdc-c5b2-4bf0-8859-e2c1f32dc5a3_1728x963.png)
![[8.18] 形で覚えるDune使い方講座<初級+>](https://substackcdn.com/image/fetch/$s_!-i8Q!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F523f618f-b99c-4d17-a903-53fb8aa1ef53_3456x1926.png)
![[8.19] 形で覚えるDune使い方講座<中級>](https://substackcdn.com/image/fetch/$s_!J-od!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F30d14507-ae26-4147-b109-1b2a4341ba2b_3456x1926.png)
今回は<中級+>編、値の四則演算、四捨五入、順位付けと連番付与、平均値計算、フォーマットに変換、型変換、文字列の結合と切り取り、を解説します。
Special thanks to @Guss3.eth, @hideyukiaka, @jpnykw
※コードブロックを使用して説明しているため、なるべくパソコンからのアクセスをお勧めします。またこの講座を受けるためにはパソコンが必要です。
値の四則演算〈+,-,*,/〉
取得した値を足す、引く、掛ける、割る、の四則演算は「+」「-」「*」「/」をそれぞれ使用することで直接計算可能です。使用時の並びは普通の計算式と同じです。
足す: +
引く: -
掛ける: *
割る: /
試しにデータセット「top_erc721_holders」の「supply_share」で取得した割合を100倍して単位を%に揃えましょう。その時のコードは下記のようになります。
SELECT
wallet_address AS Address,
balance AS Quantity,
supply_share * 100 AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
ORDER BY balance DESCsupply_shareに100をかけた結果、該当するカラムの値がきちんと100倍されています。でも小数点がいっぱい出てきちゃったので、値を四捨五入してみましょう。

値の四捨五入〈ROUND〉
カラムの数値や特定の値を四捨五入したい時はROUND関数を使用します。すごく便利な関数で四捨五入したい対象をぶち込むだけでOKです。
ROUND(<何を>) /* 1の位で四捨五入 */
ROUND(<何を>, <どこで>) 第2引数に何桁目で四捨五入したいかを指定することもできます。今回の場合は割合なので小数点第2位で四捨五入を行います。先ほどの例の時にROUNDを使って四捨五入したコードは下記のようになります。
SELECT
wallet_address AS Address,
balance AS Quantity,
ROUND(supply_share * 100, 2) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
ORDER BY balance DESC実行してみると四捨五入されていることが確認できます。

この時点でORDER BY DESCを行なっているので既に降順で上から並んでいますが、何番目のホルダーか分からないのでデータに順位をつけてみましょう。
データに順位を付ける〈RANK〉
データセットからSELECTで取得したカラムをソートして順位を付与したい場合は「RANK」を使用します。アドレスやコレクション毎の取引量ランキングやホルダーなどに順位をつけて表示したい場合にはこれを使うとかなり楽です。
また順位付けの時はソートを行なって連番を振ることが一般的なので、RANKと並べて「ORDER BY」と使うケースが多いです。
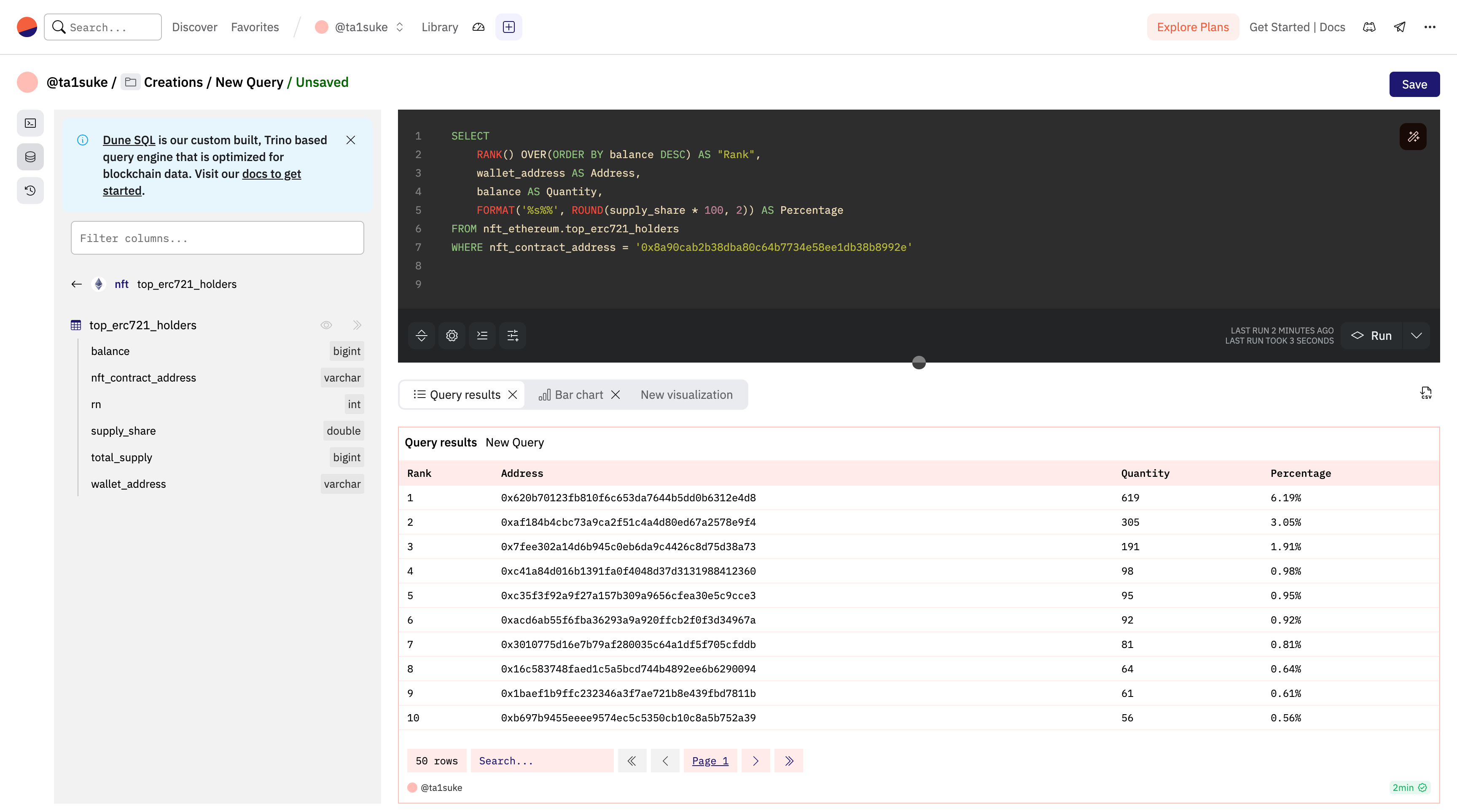
RANK() OVER(ORDER BY <何を(カラム名)> <ASC or DESC>)実際に先ほどのコードにRANKを使用してみます。下部に書いていたORDER BYは例のようにRANKとまとめられます。その時のコードは下記のようになります。
SELECT
RANK() OVER(ORDER BY balance DESC) AS "Rank",
wallet_address AS Address,
balance AS Quantity,
ROUND(supply_share * 100, 2) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'一つここで注意ポイントがあります。今回2行目でASを使って「Rank」という名前をつけていますが、関数名などですでにプログラムに組み込まれている「予約語」は区別するために「” ”」を付ける必要があります。

これにてdoodlesのホルダーランキングを作成することができました。RANKと似た挙動をする関数が2つあるので一緒に紹介しておきます。
重複順位をスキップしない〈DENSE_RANK〉
先ほど紹介した「RANK」は同率順位がくるとその個数分スキップしますが、こっちの「DENSE_RANK」は同率順位がきてもスキップしない特性があります。なのでその値自体が全体で何位かを表しているということです。
RANK: 1,2,3,4,4,4,7,7,9,10DENSE
DENSE_RANK: 1,2,3,4,4,4,5,5,6,7
DENSE_RANK() OVER(ORDER BY <何を(カラム名)> <ASC or DESC>)さっきRANKを使っていたところをDENSE_RANKに変えてみましょう。

保有枚数が重複しているところはわかりやすいですのでランキング末尾を見てみると、連続する29の次に30が来ていますよね。ここが大きな違いです。
データに連番を振る〈ROW_NUMBER〉
こちらもよく「RANK」や「DENSE_RANK」と比較されるので一緒に覚えておきましょう。ソートしたカラムに連番を振る場合は「ROW_NUMBER」を使用します。順位と異なり同率も違うものとして番号が振られます。
ROW_NUMBER() OVER(ORDER BY <カラム名> <ASC or DESC>)実際に使ってみましょう、連番になっていることは末尾の部分を確認するとわかりやすいです。50個のデータでちゃんと50番までになっています。

カラムの値を平均する〈AVG〉
昨日SUMとCOUNTを覚えたと思いますが、その時に「AVG」も一緒に説明しておくべきでした。同じ使い方で指定したカラムの値の全ての平均値を返してくれる便利な関数があります。
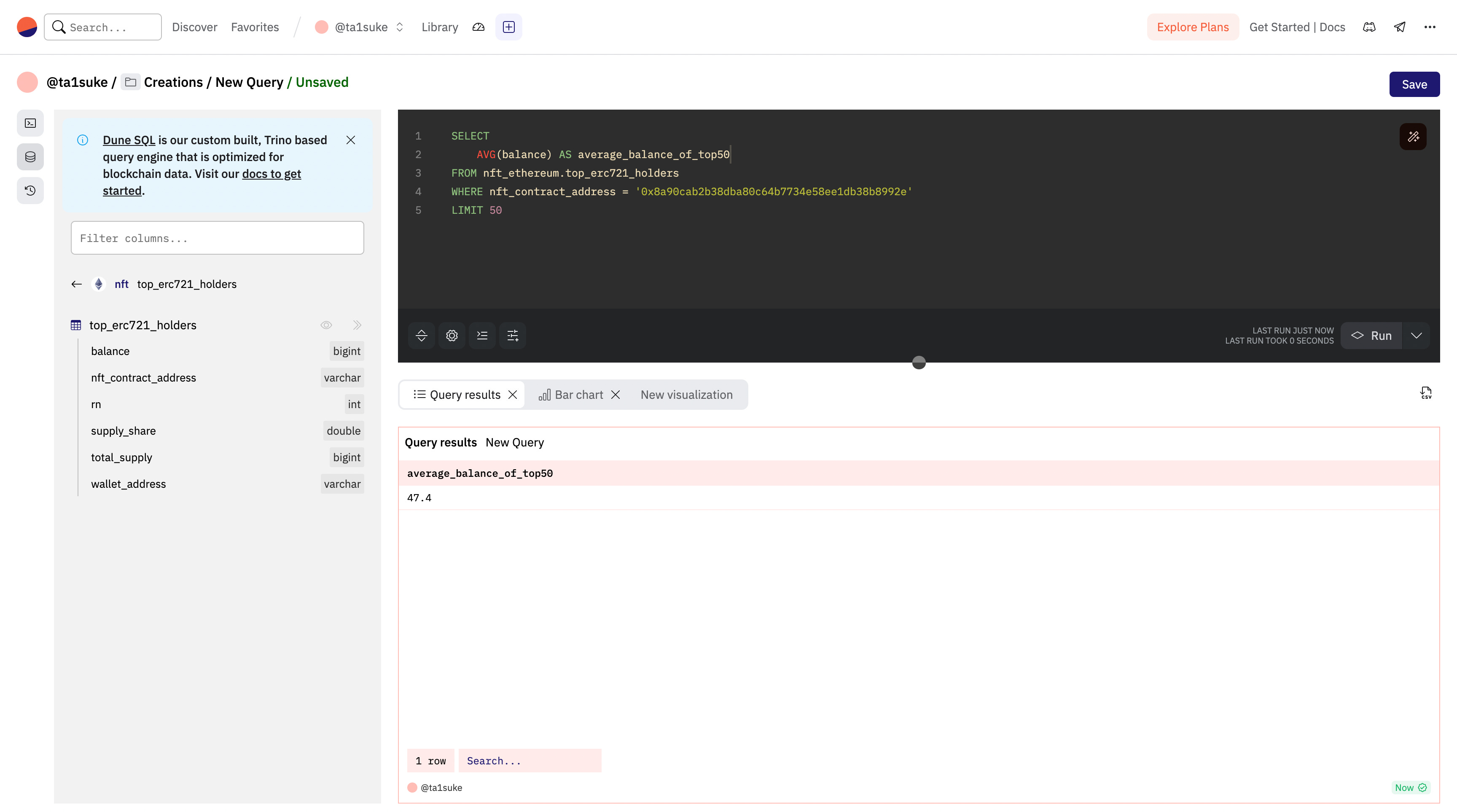
AVG(<何を(カラム名)>)先ほどまでのdoodlesの上位50ホルダーの平均保有枚数を求めてみましょう。
SELECT
AVG(balance) AS average_balance_of_top50
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'
LIMIT 50特に他の情報は必要ないので、今回は合計保有枚数のみが表示されるようにしました。
指定したフォーマットに変換〈FORMAT〉
指定したフォーマットとカラムや値を引数で渡すことで、フォーマットされた文字列を返してくれる便利な関数です。その中でもいちばん使うやつを今回は紹介して、サンプルコードにでてきたらその都度解説しますね。
SELECT format(<何に>, <何を>)
SELECT format('%s%%', <カラム、数値>) /*第2引数を%に変換*/ここで少し先ほどのホルダーリストの可読性を上げてみましょう。Percentageの各数値の後に「%」をくっつけることでみやすくしてみます。
SELECT
ROW_NUMBER() OVER(ORDER BY balance DESC) AS "Rank",
wallet_address AS Address,
balance AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'これで出力された数値に%が付くようになりました。
FORMATと同じ分類にあたる変換系の関数を2つ紹介しておきます。
値を任意の型に変換〈CAST〉
カラムの中の値を任意のデータ型に変換できる「CAST」はASを利用してデータ型の指定を行います。ここはCASTの外で使う名付けのASとは別物です。
CAST(<何を(値、カラム)> AS <何に(データ型名)>)後ほど条件分岐の部分で登場するのでそちらで詳しく紹介します。
変換失敗時にnullを返す〈TRY_CAST〉
CASTと役割は同じですが変換に失敗した時にnullを返すのが「TRY_CAST」です。
TRY_CAST(<何を(値、カラム)> AS <何に(データ型名)>)こちらも現時点ではあまり使わないので<上級>で出てきた時に詳しく解説します。
文字列を結合する〈CONCAT〉
引数に文字列を渡すことで結合させることのできる「CONCAT」は、一般的には別のカラムに保存している苗字と名前をくっつける時とかに使います。
SELECT CONCAT(<引数①>, <引数②>, <引数③>...) /* 2個以上の引数を渡す */数字同士の結合を足し算ではなく行いたい場合は、一度文字列として渡してCASTで型変換をしないと計算に再度利用することはできません。

※上記サンプルコードで利用している「TYPEOF」は引数に渡したデータの型を返してくれる関数です。エラーが出た時などのデータ型の確認にたまに利用します。
文字列の切り取り〈SUBSTRING〉
文字列の切り取りには「SUBSTRING」関数を利用します。第3引数があるかないかで挙動が変わる点に特に注意が必要です。
SELECT SUBSTRING(<何を>, <何桁目以降に>)
SELECT SUBSTRING(<何を>, <何桁目から>, <何桁目まで>)ここでは練習として先ほどのdoodlesホルダーの長くて見づらいウォレットアドレスを「0xと頭4文字+後6文字の12文字」に短縮して表示して見ましょう。
SELECT
RANK() OVER(ORDER BY balance DESC) AS "Rank",
CONCAT(SUBSTRING(wallet_address, 1, 6), '...', SUBSTRING(wallet_address, 37)) AS Address,
balance AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'ここまで答えを見ずにできたら、ある程度のダッシュボードを作るための50%の知識ぐらいまでは到達できていると思います。一旦一息付きましょう、お疲れ様です。

とは言いつつもまだまだ覚えることがあるので先に進みます。
条件分岐を〈CASE, WHEN, THEN, ELSE, END〉
条件分岐を作成してlineごとに表示する内容が変わるようにするには、「CASE」と「END」の中に条件を書くことで実現できます。条件文は「WHEN」「THEN」「ELSE」の3つを使って記述します。
CASE
WHEN <これの時(条件)> THEN <左の条件を満たしたら表示するもの>
WHEN <これの時(条件)> THEN <左の条件を満たしたら表示するもの> /* 複数条件可能 */
ELSE <どの条件を満たさなければ表示するもの>
END上の説明だとちょっとわかりづらいので、実際に上位ホルダーリストを使って条件分岐を作って見ましょう。下記の条件で表示する内容を変えてみます。
100枚以上保有: 保有枚数そのままを表示
50から99枚: 「50~99」を表示
20から49枚: 「20~49」を表示
10枚から29枚: 「10~29」を表示
9枚以下: 「~9」を表示
SELECT
RANK() OVER(ORDER BY balance DESC) AS "Rank",
CONCAT(SUBSTRING(wallet_address, 1, 6), '...', SUBSTRING(wallet_address, 37)) AS Address,
CASE
WHEN 100 <= balance THEN CAST(balance AS VARCHAR)
WHEN 50 <= balance THEN '50~99'
WHEN 20 <= balance THEN '20~49'
WHEN 10 <= balance THEN '10~29'
ELSE '~9'
END AS Quantity,
FORMAT('%s%%', ROUND(supply_share * 100, 2)) AS Percentage
FROM nft_ethereum.top_erc721_holders
WHERE nft_contract_address = '0x8a90cab2b38dba80c64b7734e58ee1db38b8992e'ここで注意なのはCASEを使うことで表示上新たなカラムが生成されるのですが、ここには基本的に同じ型しか入れることができません。上の条件文の場合、balanceは数字ですが、他は「‘ ’」で囲っているので文字列ですよね。
なので数字を文字列に型変換する必要があります。ここで先ほど紹介したCASTを使用します。文字列に値する「VARCHAR」という型に変換してみましょう。

このようにQuantityの部分を範囲表示することに成功しました。このようにlineの値毎に表示する内容を変更したいときに条件分岐を使用します。
まとめ
今日はここらへんで終わりたいと思います。多分いままででいちばん進みましたね、分からないところがあれば私のX!で気軽に聞いてください!
ちょっと反省として型の話をあまり説明せずに、前提知識のあるエンジニア向けに書いちゃったので次回の部分で補完できればと思います。
明日夜はついに<上級>編、かなり難しくなると思いますがぜひ最後まで一緒に頑張りましょう!今日も見ていただきありがとうございました。
次のレベルのDune講座はこちらから↓
![[8.21] 形で覚えるDune使い方講座<中級++>](https://substackcdn.com/image/fetch/$s_!3oEx!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffcc7ac10-0006-46a3-bf32-2c7c60390ac2_3456x1928.png)